源码下载链接https://sourceforge.net/projects/cjson/
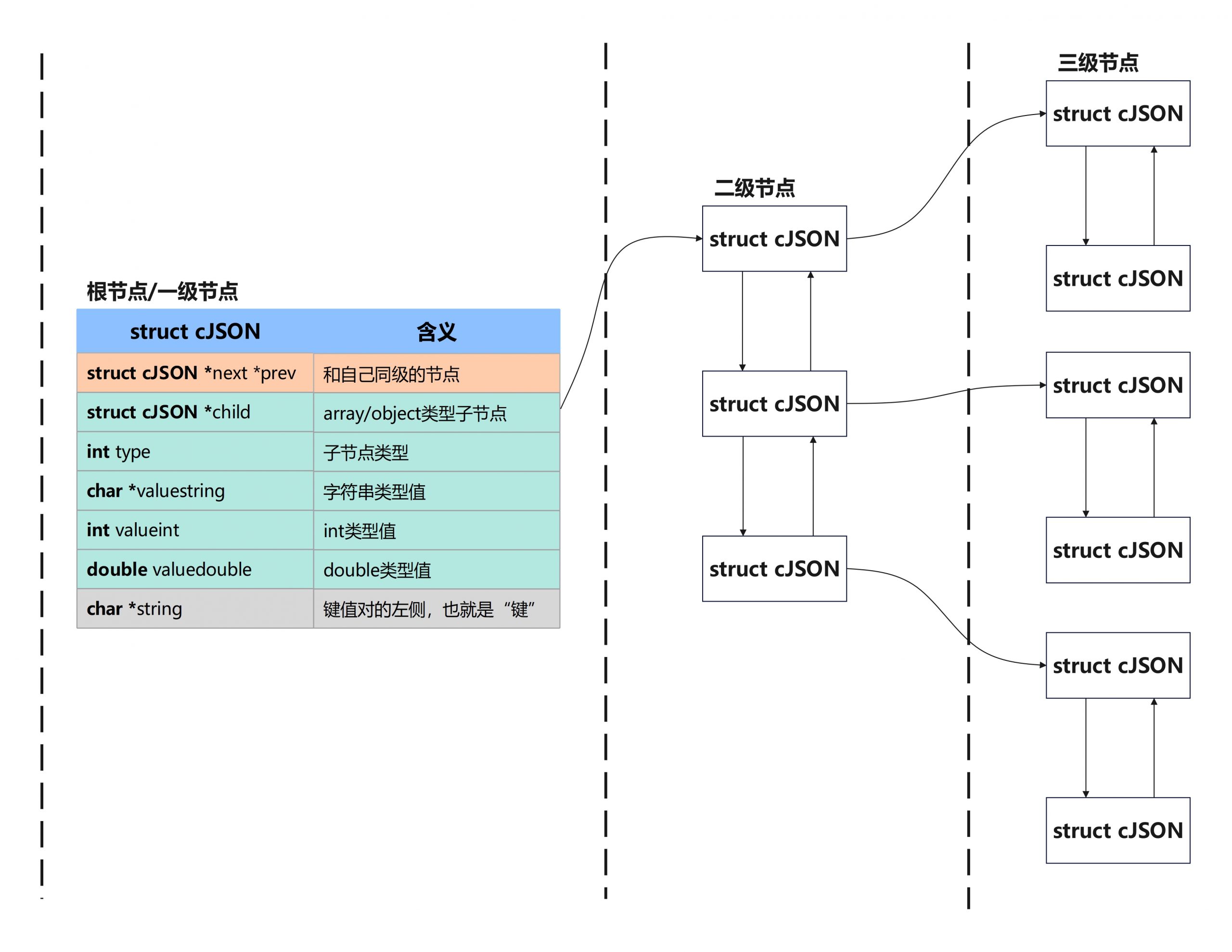
1. 核心数据结构
相同等级的元素使用双向链表链接,不同等级的元素使用child指针连接。例如:多个object并列时或着object内部的成员使用双向链表连接,object名称与其内部的成员通过child连接
typedef struct cJSON {
struct cJSON *next,*prev; // 双向链表头节点和尾节点
struct cJSON *child; // 存储子项
int type; // 节点类型
char *valuestring; // 存储对象数组或键值对的内容
int valueint; // number值的整形存储
double valuedouble; // number值的浮点型存储
char *string; // 存储对象数组或键值对的名称
} cJSON;
/* cJSON Types: */
#define cJSON_False 0
#define cJSON_True 1
#define cJSON_NULL 2
#define cJSON_Number 3
#define cJSON_String 4
#define cJSON_Array 5
#define cJSON_Object 6每一个json节点对应着一个cJSON结构,从最外层到最内层可以看做是一级一级,转化成对应的数据结构存储则如下图
2. 全局变量
char *ep;
在记录出错时是在哪个字符,以错误码的方式返回;通过cJSON_GetErrorPtr()获取。本文的示例代码中不涉及此接口,后文中也不深入讨论此机制,在此提出仅用于向读者补充cJSON整体架构设计
3. 从字符串解析json流程
cJSON提供的一个关键的功能便是,对json文本的解析。对于树状结构的json格式cJSON创建了struct cJSON数据结构,其中使用了使用双向链表存储同级别节点,创建struct cJSON *child元素,存储低级别节点。解析流程中使用双层递归的设计从根节点开始由外至内一层层解析,对字符串的处理和整体架构设计有许多精妙优雅的设计,在阅读源码时可以学习借鉴。本章节从字符串解析流程切入,对cJSON中的名称以Parse_开头的一组接口进行剖析,在源码学习中感受cJSON中设计的巧思。
参考cjson源代码中给出demo的流程
核心函数为cJSON_Parse、cJSON_Print和cJSON_Delete
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
void doit(char *text)
{
char *out;
cJSON *json;
json = cJSON_Parse(text);
out = cJSON_Print(json);
cJSON_Delete(json);
printf("%s\n", out);
free(out);
}
int main (int argc, const char * argv[])
{
char text1[] = "{\n\"name\": \"Jack (\\\"Bee\\\") Nimble\", \n\"format\": {\"type\": \"rect\", \n\"width\": 1920, \n\"height\": 1080, \n\"interlace\": false,\"frame rate\": 24\n}\n}";
doit(text1);
create_objects();
return 0;
}3.1 关键函数接口及实现逻辑
cJSON_New_Item()函数
内部构造函数,创建一个cjson节点,并返回节点地址
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
cJSON *cJSON_New_Item(void)
{
cJSON* node = (cJSON*)malloc(sizeof(cJSON));
return node;
}函数核心思想
申请内存返回内存指针,创建链表或其他数据结构节点的常规操作,无需多言
cJSON_Parse()函数
创建新的cJSON节点,调用parse_value()填充节点
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* Parse an object - create a new root, and populate. */
cJSON *cJSON_ParseWithOpts(const char *value)
{
cJSON *c = cJSON_New_Item();
parse_value(c, skip(value));
return c;
}
/* Default options for cJSON_Parse */
cJSON *cJSON_Parse(const char *value)
{
return cJSON_ParseWithOpts(value);
}函数核心思想
本质是对parse_value()的一层封装
parse_value()函数
文本解析处理函数,对文本进行初步分类。对不同的情况使用不同的处理流程
json格式中的对象对应{开头json格式中的数组对应[开头json格式中字符串与数值被统称为值使用""包裹
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static const char *parse_value(cJSON *item, const char *value)
{
if (*value == '\"') {
return parse_string(item, value);
}
if (*value == '-' || (*value >= '0' && *value <= '9')) {
return parse_number(item, value);
}
if (*value == '[') {
return parse_array(item, value);
}
if (*value == '{') {
return parse_object(item, value);
}
return NULL; /* failure. */
}函数核心思想
根据待解析字符串的前几位字符来判断,此段数据对于json中的哪种类型。cJSON还对字符串为null、true、false这三种特殊情况有处理,本文中并未体现这一点
parse_object()函数
object解析函数,将传入的value当作一个非常长的字符串,不断的分割字符串。将解析出来的数据用来填充item,同级别元素填充在双向链表中,低级别元素填充在child节点中。
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
- 将
item作为根节点,创建一个桶结构存储解析出的json内容 - 函数使用双层递归设计
/* Build an object from the text. */
static const char *parse_object(cJSON *item, const char *value)
{
/* child在函数前半段为新增节点,函数后半段为链表哨兵位指针 */
cJSON *child;
child = cJSON_New_Item();
item->child = child;
item->type = cJSON_Object;
/* 取出前半部分存入string,可能是对象或数组的名称,或是键值对的前半部分 */
value = skip(parse_string(child, skip(value + 1)));
child->string = child->valuestring;
child->valuestring = NULL;
if (*value != ':') {
return NULL;
}
/*
* 此处可能造成递归调用
* 递归的出口: value开头到第一个“,”的部分是普通键值对,不包含object或array深层嵌套
*/
value = skip(parse_value(child, skip(value + 1)));
while (*value == ',') {
cJSON *new_item;
new_item = cJSON_New_Item();
/*
* 创建双向不循环链表,保存之前的解析结果。链表中仅保存同级元素
* 此处child视为链表的哨兵位指针而不是新增节点指针
*/
child->next = new_item;
new_item->prev = child;
child = new_item;
value = skip(parse_string(child, skip(value + 1)));
child->string = child->valuestring;
child->valuestring = NULL;
if (*value != ':') {
return NULL;
}
value = skip(parse_value(child, skip(value + 1)));
}
if (*value == '}') {
return value + 1;
}
return NULL;
}函数核心思想
此函数最主要的作用便是填充cJSON结构体,struct cJSON是cJSON中最为核心和基础的数据结构,其核心结构是两个链表节点和一个child节点。在解析json文件时将其中成员视为具有不同的等级;相同缩进的成员为同一等级,将同一等级的元素使用双向链表连接,低等级元素则存放在child节点中;填充的struct cJSON实现的方式,使用了双层递归的方式去实现
双层递归的函数设计
对于object来说其至少包含两层等级,即object名称和成员;对于将名称作为字符串处理。首先提取object名称部分,对于后半段成员的处理则是调用parse_value()去处理,此时如果内部成员是object则会触发第一层递归,此时child节点便作为一个新的根节点,直到遇到普通的键值对递归结束,这便是函数前半段的处理

当一层递归结束后,函数后半段创建一个循环遍历json文件的每一行,循环中创建一个新节点添加在双向链表后,并提取下个元素的名称填充child->valuestring。接着继续调用parse_value()如果此时解析的元素是object便是第二层递归,递归出口与第一层相同。整个循环中会将相同级别成员添加至双向链表,低级别元素添加至child节点
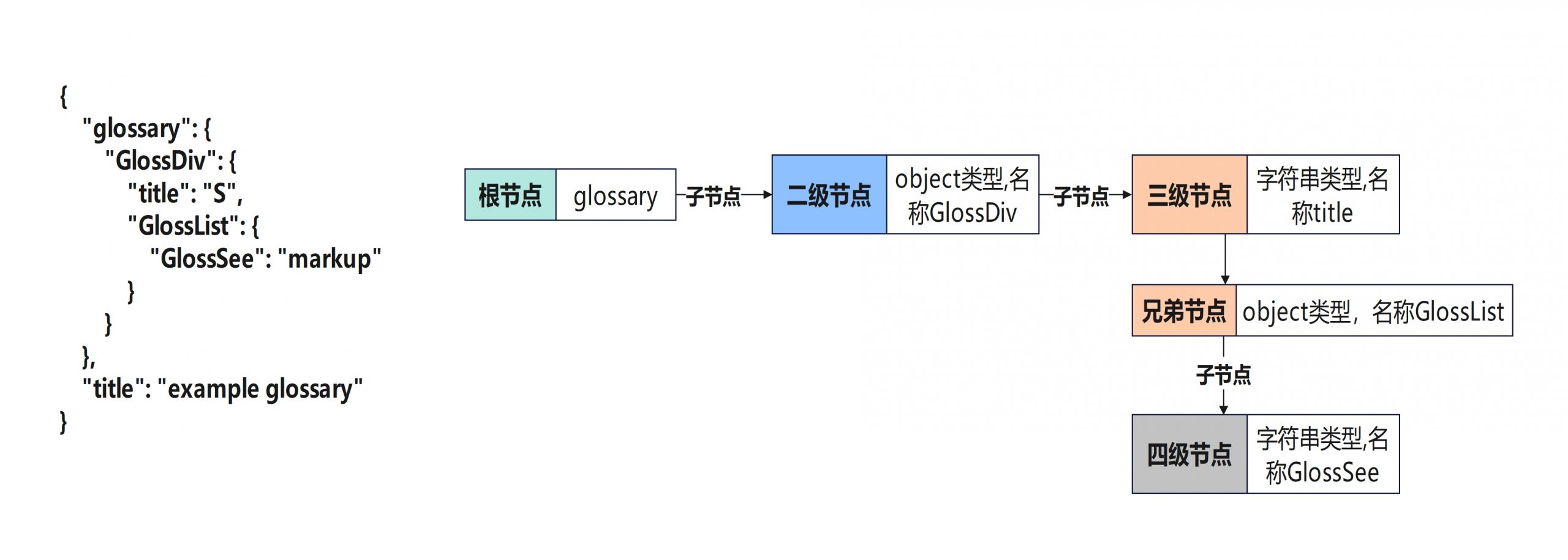
二层递归结束后,函数调用栈返回。继续处理一层递归未处理的部分
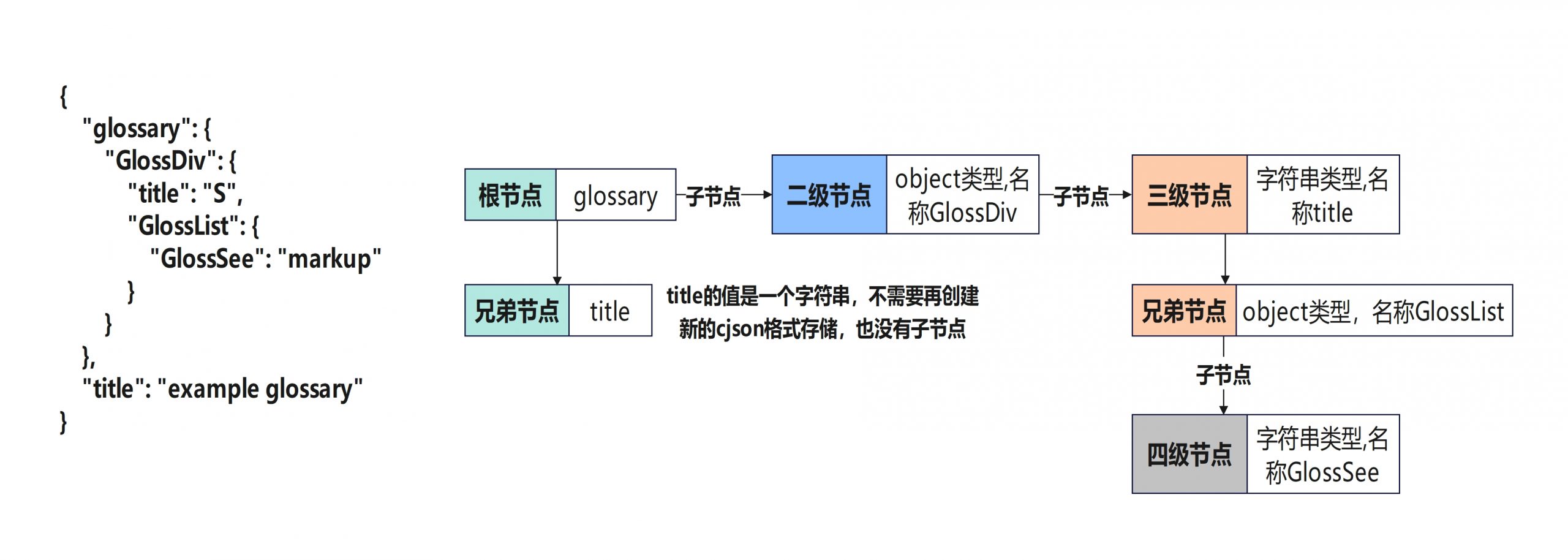
实际上,绝大部分json都是以{开头,因此每次解析时第一个进入的函数都是parse_object()因此对这个函数的理解,对整个cJSON解析流程的理解至关重要
parse_array()函数
其核心逻辑与parse_object()函数非常相似,最大的区别在于在函数前半段不需要取出:符号的前半部分
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* Build an array from input text. */
static const char *parse_array(cJSON *item, const char *value)
{
/* child在函数前半段为新增节点,函数后半段为链表哨兵位指针 */
cJSON *child;
child = cJSON_New_Item();
item->child = child;
item->type = cJSON_Array;
/*
* 此处可能造成递归调用
* 递归的出口: value开头到第一个“,”的部分是普通键值对,不包含object或array深层嵌套
*/
value = skip(parse_value(child, skip(value + 1)));
while (*value == ',') {
cJSON *new_item;
new_item = cJSON_New_Item()
/* 此处child视为链表的哨兵位指针而不是新增节点指针 */
child->next = new_item;
new_item->prev = child;
child = new_item;
value = skip(parse_value(child, skip(value + 1)));
}
if (*value == ']') {
return value + 1;
}
return NULL;
}函数核心思想
此函数整体结构设计与parse_object()高度相似,同样采取双层递归的设计在此不做赘述。但与parse_object()又存在一处非常大的不同,即不对item->string进行赋值
消失的名字
由于json中的array结构是嵌套在object中,parse_array()函数只会被parse_object()函数调用。所以在解析array时名称的部分会在进入parse_array()函数前就会在parse_object()中解析处理,array内部的元素是以,分隔的,所有的键值对都只会被嵌套在另一个object中
3.2 字符串处理接口
cjson中设计大量的字符串处理逻辑,其中有许多设计可以学习借鉴,在此列出;
本文列出的几个函数基本上可直接复制粘贴在其他项目中使用,是非常优质的轮子,故贴出函数源代码
skip函数
跳过空格和无用字符
源代码中函数实现如下
笔者注:代码已做格式化处理
static const char *skip(const char *in)
{
while (in && *in && (unsigned char)*in <= 32) {
in++;
}
return in;
}函数核心思想
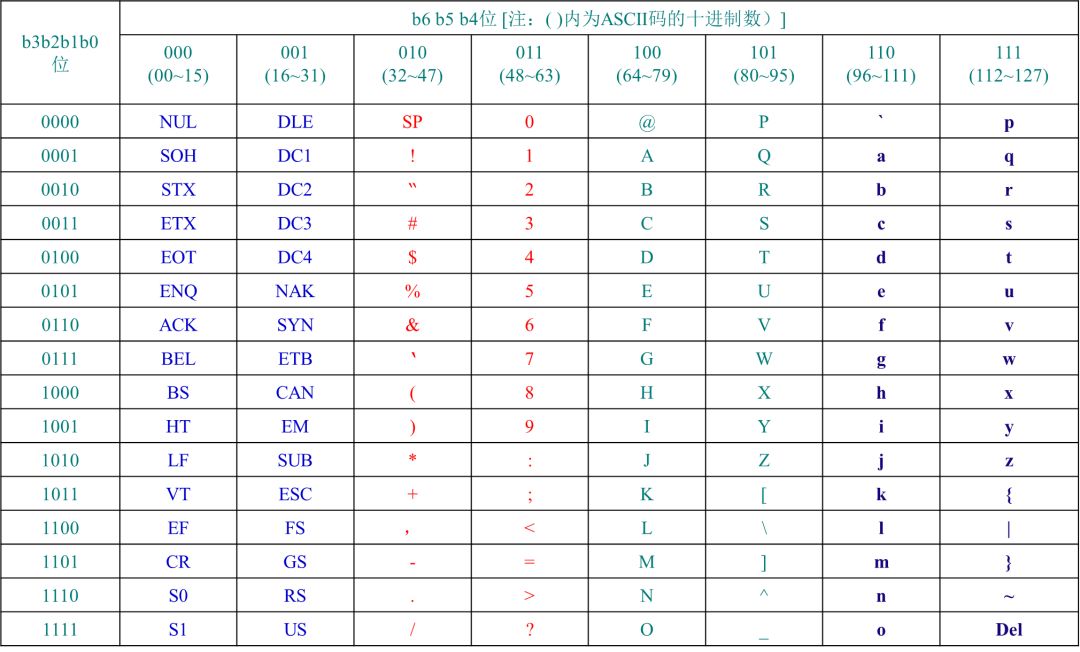
函数通过while循环遍历整个字符串,首先判断指针不为空,指针指向的值不为空
不断向后偏移,直到指向的字符的ACSII码大于32;函数作者非常巧妙的利用了ASCII码表的排列的规则,将前32位在字符串解析时无法用到的字符舍弃,只保留了有效字符
parse_number函数
将字符串解析为一个数字,同时支持复数,浮点数,可解析科学记数法的特性。
源代码中函数实现如下
/* Parse the input text to generate a number, and populate the result into item. */
static const char *parse_number(cJSON *item,const char *num)
{
double n=0,sign=1,scale=0;int subscale=0,signsubscale=1;
if (*num=='-') sign=-1,num++; /* Has sign? */
if (*num=='0') num++; /* is zero */
if (*num>='1' && *num<='9') do n=(n*10.0)+(*num++ -'0'); while (*num>='0' && *num<='9'); /* Number? */
if (*num=='.' && num[1]>='0' && num[1]<='9') {num++; do n=(n*10.0)+(*num++ -'0'),scale--; while (*num>='0' && *num<='9');} /* Fractional part? */
if (*num=='e' || *num=='E') /* Exponent? */
{ num++;if (*num=='+') num++; else if (*num=='-') signsubscale=-1,num++; /* With sign? */
while (*num>='0' && *num<='9') subscale=(subscale*10)+(*num++ - '0'); /* Number? */
}
n=sign*n*pow(10.0,(scale+subscale*signsubscale)); /* number = +/- number.fraction * 10^+/- exponent */
item->valuedouble=n;
item->valueint=(int)n;
item->type=cJSON_Number;
return num;
}函数核心逻辑
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
首先申请数个变量存储不同的特性值
static const char *parse_number(cJSON *item, const char *num)
{
/*
* n:存储数字
* sign:存储正负号
* scale:存储小数点后的位数
* subscale:存储科学计数法部分的值
* signsubscale:存储科学计数法的正负号
*/
double n, sign, scale;
n = 0;
sign = 1;
scale = 0;
int subscale, signsubscale;
subscale = 0;
signsubscale = 1;
...
}依次遍历整个字符串,将不同部分的值存储最开始不同的变量中
static const char *parse_number(cJSON *item, const char *num)
{
...
/* 取出符号位,使用sign记录 */
if (*num == '-') {
sign =- 1, num++;
}
/* 跳过多余的0 */
if (*num == '0') {
num++;
}
/* 将字符串中的连续数字转换为整形 */
if (*num >= '1' && *num <= '9') {
do {
/* *num++ -'0';等价于*num-'0';num++; */
n = (n * 10.0) + (*num++ -'0');
} while (*num >= '0' && *num <= '9');
}
/*
* 将小数点后的连续数字转化为整形
* 与上述流程区别在于使用scale变量记录小数点后数字位数
*/
if (*num == '.' && num[1] >= '0' && num[1] <= '9') {
num++;
do {
/* *num++ -'0';等价于*num-'0';num++;*/
n = (n * 10.0) + (*num++ -'0'), scale--;
} while (*num >= '0' && *num <= '9');
}
/* 首先记录科学计数法的符号 */
if (*num == 'e' || *num == 'E') {
num++;
if (*num == '+') {
num++;
} else if (*num == '-') {
signsubscale = -1, num++;
}
/*
* 将字符串中的连续数字转化为整形
* 此处不使用do while 可能是考虑输入非法字符的情况
*/
while (*num >= '0' && *num <= '9') {
/* *num++ -'0';等价于*num-'0';num++;*/
subscale = (subscale * 10) + (*num++ - '0');
}
}
...
}将此前记录的不同位置的值通过运算转化成浮点数
static const char *parse_number(cJSON *item, const char *num)
{
...
/*
* 带符号的n:sign * n
* 科学计数法的系数:pow(10.0, (scale + subscale * signsubscale));
* 此处计算的是科学计数法所以底数是10
*/
n = sign * n * pow(10.0, (scale + subscale * signsubscale));
item->valuedouble = n;
item->valueint = (int)n;
item->type = cJSON_Number;
return num;
}函数核心思想
可使用字符串表示一个数字例如"-1.23e10"表示负一百二十三
其中从左到右依次为
"-"符号位"1"数字整数位".23"整数后的小数"e10"科学计数法
parse_number()的核心思想在于将字符串的每一部分取出,最后通过计算获得字符串代表的数字
parse_string函数
此函数用于处理形式为"XXXXXX"的字符串。函数会处理字符串中的转义字符,并将Unicode转义序列转换为对应的UTF-8字符
该函数的主要功能包括:
- 解析字符串中的转义字符,如
\n、\t等。 - 将
Unicode转义序列\uXXXX转换为UTF-8字符。 - 处理
UTF-16代理对surrogate pairs
源代码中函数实现如下
/* parse_hex4用于解析一个4位十六进制数,并将其转换为对应的无符号整数 */
static unsigned parse_hex4(const char *str)
{
unsigned h=0;
if (*str>='0' && *str<='9') h+=(*str)-'0'; else if (*str>='A' && *str<='F') h+=10+(*str)-'A'; else if (*str>='a' && *str<='f') h+=10+(*str)-'a'; else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0'; else if (*str>='A' && *str<='F') h+=10+(*str)-'A'; else if (*str>='a' && *str<='f') h+=10+(*str)-'a'; else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0'; else if (*str>='A' && *str<='F') h+=10+(*str)-'A'; else if (*str>='a' && *str<='f') h+=10+(*str)-'a'; else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0'; else if (*str>='A' && *str<='F') h+=10+(*str)-'A'; else if (*str>='a' && *str<='f') h+=10+(*str)-'a'; else return 0;
return h;
}
/* Parse the input text into an unescaped cstring, and populate item. */
static const unsigned char firstByteMark[7] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
static const char *parse_string(cJSON *item,const char *str)
{
const char *ptr=str+1;char *ptr2;char *out;int len=0;unsigned uc,uc2;
if (*str!='\"') {ep=str;return 0;} /* not a string! */
while (*ptr!='\"' && *ptr && ++len) if (*ptr++ == '\\') ptr++; /* Skip escaped quotes. */
out=(char*)cJSON_malloc(len+1); /* This is how long we need for the string, roughly. */
if (!out) return 0;
ptr=str+1;ptr2=out;
while (*ptr!='\"' && *ptr)
{
if (*ptr!='\\') *ptr2++=*ptr++;
else
{
ptr++;
switch (*ptr)
{
case 'b': *ptr2++='\b'; break;
case 'f': *ptr2++='\f'; break;
case 'n': *ptr2++='\n'; break;
case 'r': *ptr2++='\r'; break;
case 't': *ptr2++='\t'; break;
case 'u': /* transcode utf16 to utf8. */
uc=parse_hex4(ptr+1);ptr+=4; /* get the unicode char. */
if ((uc>=0xDC00 && uc<=0xDFFF) || uc==0) break; /* check for invalid. */
if (uc>=0xD800 && uc<=0xDBFF) /* UTF16 surrogate pairs. */
{
if (ptr[1]!='\\' || ptr[2]!='u') break; /* missing second-half of surrogate. */
uc2=parse_hex4(ptr+3);ptr+=6;
if (uc2<0xDC00 || uc2>0xDFFF) break; /* invalid second-half of surrogate. */
uc=0x10000 + (((uc&0x3FF)<<10) | (uc2&0x3FF));
}
len=4;if (uc<0x80) len=1;else if (uc<0x800) len=2;else if (uc<0x10000) len=3; ptr2+=len;
switch (len) {
case 4: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 3: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 2: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 1: *--ptr2 =(uc | firstByteMark[len]);
}
ptr2+=len;
break;
default: *ptr2++=*ptr; break;
}
ptr++;
}
}
*ptr2=0;
if (*ptr=='\"') ptr++;
item->valuestring=out;
item->type=cJSON_String;
return ptr;
}函数核心逻辑
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
将传入的字符串进行遍历,对于其中的转义字符和Unicode字符做专门转化处理,将转化后的结果存入一块申请好的内存中。使用item->valuestring指向这块内存用作出参,函数返回遍历字符串的结尾
static const char *parse_string(cJSON *item, const char *str)
{
const char *ptr = str+1;
char *ptr2;
char *out;
int len = 0;
unsigned uc, uc2;
/*
* 此处对'\\'特殊处理是考虑到后续字符串处理流程中'\'可能会被误认为转义字符
* 所以遇到'\\'时需要额外偏移一位
*/
while (*ptr != '\"' && *ptr && ++len) {
if (*ptr++ == '\\') {
ptr++;
}
}
out = (char*)malloc(len + 1);
ptr = str + 1;
ptr2 = out;
/*
* 将ptr拷贝到ptr2中,对于转义字符和
*/
while (*ptr!='\"' && *ptr) {
if (*ptr!='\\') {
*ptr2++ = *ptr++;
} else {
ptr++;
switch (*ptr) {
case 'b':
*ptr2++ = '\b';
break;
case 'f':
*ptr2++ = '\f';
break;
case 'n':
*ptr2++ = '\n';
break;
case 'r':
*ptr2++ = '\r';
break;
case 't':
*ptr2++ = '\t';
break;
case 'u': /* transcode utf16 to utf8. */
...
/*
* \u 后面跟着四个十六进制数字(0-9、a-f 或 A-F),表示一个 Unicode 字符的代码点
* 此处篇幅限制,对 utf16转utf8的处理后文中讨论
*/
...
default:
*ptr2++ = *ptr;
break;
}
ptr++;
}
}
*ptr2 = 0;
if (*ptr == '\"') {
ptr++;
}
/*
* 此处不能free(out)
* 结构体定义中valuestring是一个char*类型,该指针指向的内存的生命周期应当与valuestring指针保持一致
* 此处out持有的内存应当在valuestring指针置NULL时再free,否则可能出现内存踩空或野指针的问题
*/
item->valuestring = out;
item->type = cJSON_String;
return ptr;
}对于 \u转义字符的处理
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
此处对Unicode字符处理流程中作者利用Unicode字符本身的特点进行针对性处理,流程中使用了大量Macgic Number,在此列出并注解。
firstByteMark[7]{ 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC }数组元素对应不同长度的UTF-8字符的起始字节标记0x00:保留0xC0:用于 2 字节 UTF-8 编码的起始字节0xE0:用于 3 字节 UTF-8 编码的起始字节0xF0:用于 4 字节 UTF-8 编码的起始字节0xF8:用于 5 字节 UTF-8 编码的起始字节0xFC:用于 6 字节 UTF-8 编码的起始字节Unicode编码划分了许多不同的区间;其中有几个特殊的区间,低位专用区间、高位替代区间、高位专用替代区间。这些区间的字符不具有实际含义
static const unsigned char firstByteMark[7] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
case 'u': /* transcode utf16 to utf8. */
uc = parse_hex4(ptr + 1);
ptr += 4;
/* Unicoded 低位专用区间 */
if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == 0) {
break;
}
/* Unicoded 高位替代区间、高位替代专用区间 */
if (uc >= 0xD800 && uc <= 0xDBFF) {
uc2 = parse_hex4(ptr + 3);
ptr += 6;
/* 根据 UTF-16 编码规则,将两个代理项组合成一个 Unicode 码点 */
uc = 0x10000 + (((uc&0x3FF)<<10) | (uc2&0x3FF));
}
/* 根据 Unicode 码点的范围确定字符所占的字节数 */
len = 4;
if (uc < 0x80) {
len = 1;
} else if (uc < 0x800) {
len = 2;
} else if (uc < 0x10000) {
len = 3;
ptr2 += len;
}
/* 将 Unicode 码点按照 UTF-8 编码规则转换为对应的字节序列 */
switch (len) {
case 4:
*--ptr2 =((uc | 0x80) & 0xBF);
uc >>= 6;
case 3:
*--ptr2 =((uc | 0x80) & 0xBF);
uc >>= 6;
case 2:
*--ptr2 =((uc | 0x80) & 0xBF);
uc >>= 6;
case 1:
*--ptr2 =(uc | firstByteMark[len]);
}
ptr2 += len;
break;函数核心思想
对转义字符和Unicode编码字符的转换
3.3 解析json格式文件
cJSON源码中给出了一个解析json文件的示例,从文件中读取内容然后存放在内存中,本质上与从字符串中解析json没有区别
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
void doit(char *text)
{
char *out;
cJSON *json;
json = cJSON_Parse(text);
out = cJSON_Print(json);
cJSON_Delete(json);
printf("%s\n", out);
free(out);
}
/* Read a file, parse, render back, etc. */
void dofile(char *filename)
{
FILE *f;
long len;
char *data;
f = fopen(filename, "rb");
fseek(f, 0, SEEK_END);
len = ftell(f);
fseek(f, 0, SEEK_SET);
data = (char*)malloc(len + 1);
fread(data, 1, len, f);
fclose(f);
doit(data);
free(data);
}4. 构造json
概括的说cJSON构造json的过程是,创建一个struct cJSON类型的节点,首先将需要的数据填充这个新建的节点。然后将这个新节点添加到已有的旧节点的合适的位置中,而旧节点的类型也是一个struct cJSON类型的节点。所以cJSON构造json的过程便是一层层的嵌套struct cJSON节点的过程,对于孩子节点和兄弟节点的处理和新节点的创建和嵌套便是本章讨论的重点。
从cJSON源代码中给出的测试demo中,可以找到关于的关于构造json字符串的示例函数
关键接口
cJSON_CreateObject()创建object对象节点cJSON_AddItemToObject()向object中添加cJSON对象cJSON_AddNumberToObject()向object中添加number对象cJSON_AddStringToObject()向object中添加string对象cJSON_CreateIntArray()创建array对象节点
核心逻辑如下
void create_objects()
{
cJSON *root, *img, *thm, *IDs;
char *name_str, *out;;
int ids[4] = {116, 943, 234, 38793};
root = cJSON_CreateObject();
img = cJSON_CreateObject();
cJSON_AddItemToObject(root, "Image", img);
cJSON_AddNumberToObject(img, "Width", 800);
cJSON_AddNumberToObject(img, "Height", 600);
cJSON_AddStringToObject(img, "Title", "View from 15th Floor");
thm = cJSON_CreateObject();
cJSON_AddItemToObject(img, "Thumbnail", thm);
cJSON_AddStringToObject(thm, "Url", "http:/*www.example.com/image/481989943");
cJSON_AddNumberToObject(thm, "Height", 125);
cJSON_AddStringToObject(thm, "Width", "100");
IDs = cJSON_CreateIntArray(ids, 4);
cJSON_AddItemToObject(img, "IDs", IDs);
out = cJSON_Print(root);
cJSON_Delete(root);
printf("%s\n", out);
free(out);
}
输出结果为
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http:/*www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}cJSON_CreateObject()函数
创建新的cJSON节点,并将type设置为cJSON_Object
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
cJSON *cJSON_CreateObject(void)
{
cJSON *item = cJSON_New_Item();
if(item) {
item->type = cJSON_Object;
}
return item;
}cJSON_AddItemToObject()函数
填充新节点的string元素,然后调用cJSON_AddItemToArray()函数。
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
void cJSON_AddItemToObject(cJSON *object, onst char *string, JSON *item)
{
size_t len;
char* copy;
len = strlen(string) + 1;
copy = (char*)malloc(len)
memcpy(copy, string, len);
item->string = copy;
cJSON_AddItemToArray(object, item);
}函数核心思想
本质是对cJSON_AddItemToArray()函数的一层封装
cJSON_AddItemToArray()函数
向array中添加新节点
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* Add item to array/object. */
void cJSON_AddItemToArray(cJSON *array, cJSON *item)
{
cJSON *c = array->child;
if (!c) {
array->child = item;
} else {
while (c && c->next) {
c = c->next;
}
c->next = item;
item->prev = c;
}
}函数核心思想
若array没有孩子节点,则将新节点作为array的孩子节点
若array有孩子节点,则将找到该节点的双向链表尾部插入,将新节点作为array的孩子节点
cJSON_AddItemToArray()函数和cJSON_AddStringToObject()函数
本质是对cJSON_AddItemToObject()函数的一层封装
核心逻辑如下
#define cJSON_AddNumberToObject(object,name,n) cJSON_AddItemToObject(object, name, cJSON_CreateNumber(n))
#define cJSON_AddStringToObject(object,name,s) cJSON_AddItemToObject(object, name, cJSON_CreateString(s))函数核心思想
对于cJSON来说不管节点类型是object或是array其存储类型均为struct cJSON所以添加新的成员时,底层接口均可使用cJSON_AddItemToObject()
cJSON_CreateIntArray()函数
新建array元素,并填充整形数组numbers的元素
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* 创建新的array节点 */
cJSON *cJSON_CreateArray(void)
{
cJSON *item = cJSON_New_Item();
item->type = cJSON_Array;
return item;
}
/* 创建新的number节点 */
cJSON *cJSON_CreateNumber(double num)
{
cJSON *item = cJSON_New_Item();
item->type = cJSON_Number;
item->valuedouble = num;
item->valueint = (int)num;
return item;
}
/* Create Arrays: */
cJSON *cJSON_CreateIntArray(const int *numbers, int count)
{
int i;
cJSON *n, *p, *a;
*n = 0;
*p = 0;
*a = cJSON_CreateArray();
for(i = 0; a && i < count; i++) {
n = cJSON_CreateNumber(numbers[i]);
/* 第一个元素放在child节点中 */
if(!i) {
a->child = n;
} else {
p->next = n;
n->prev = p;
}
/* p始终指向链表的尾部 */
p = n;
}
return a;
}函数核心思想
创建array元素,利用循环将待目标数组的内容填入;首先将第一个元素防在child节点中,再将后续元素依次放入新创建的child的兄弟节点中
5. cJSON输出
cJSON输出时相关函数返回值类型为char*然后由调用者接收。这便带来了一个问题,如何保证调用者接收到的指针指向的内存地址空或垃圾内存。在对于Struct cJSON的解析过程结果的持久化与内存管理,便是cJSON不可避免的问题。对于cJSON如何处理这个问题上,在下文中对cJSON源码的一步步剖析中可窥见一二。
print_value()函数
根据节点类型针对不同类型针对处理,其中函数入参depth,fmt,p会影响后续处理逻辑
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* Render a value to text. */
static char *print_value(cJSON *item, int depth, int fmt, printbuffer *p)
{
char *out = NULL;
printbuffer *str = NULL;
if (p) {
str = p;
} else {
str = NULL;
}
switch ((item->type) & 255) {
case cJSON_Number:
out = print_number(item, str);
break;
case cJSON_String:
out = print_string(item, str);
break;
case cJSON_Array:
out = print_array(item, depth, fmt, str);
break;
case cJSON_Object:
out = print_object(item, depth, fmt, str);
break;
}
return out;
}cJSON_Print()函数
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑;
/* Render a cJSON item/entity/structure to text. */
char *cJSON_Print(cJSON *item)
{
return print_value(item, 0, 1, 0);
}print_object(item, 0, 1, 0)函数
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑;此处仅列出
cJSON_Print接口的逻辑,即print_number第二个参数printbuffer *p为NULL的逻辑,故删除部分冗余代码
/* Render an object to text. */
static char *print_object(cJSON *item, int depth, int fmt, printbuffer *p)
{
char *out= NULL, *ptr, *ret, *str;
int len = 7, i = 0, j;
size_t tmplen = 0;
cJSON *child;
child = item->child;
/* 计算本层元素的个数,使用numentries记录 */
int numentries = 0;
while (child) {
numentries++, child = child->next;
}
/*
* 此处entries和names可视为char entries[][]和char names[][]
* names存储":"前半段的值,即object、array或键值对的名称
* entries存储“:”后半段的值,即object、array或键值对的内容
*/
char **entries = NULL, **names = NULL;
entries = (char**)malloc(numentries * sizeof(char*));
names = (char**)malloc(numentries * sizeof(char*));
memset(entries, 0, sizeof(char*) * numentries);
memset(names, 0, sizeof(char*) * numentries);
/* depth记录当前层数深度 */
child = item->child;
depth ++;
len += depth;
/* 循环中仅搜索本层节点,对于深层的child节点,在print_value()中递归处理 */
while (child) {
str = print_string_ptr(child->string, 0);
ret = print_value(child, depth, fmt, 0);
names[i] = str;
entries[i] = ret;
i++;
len += strlen(ret) + strlen(str) + 2 + (fmt ? 2 + depth : 0);
child = child->next;
}
out = (char*)malloc(len);
/* 构造object的左大括号 */
*out = '{';
ptr = out + 1;
*ptr++ = '\n';
*ptr = 0;
/* 遍历搜索整个json */
for (i = 0; i < numentries; i++) {
/* 填充每一行左侧的tab */
for (j = 0; j < depth; j++) {
*ptr++ = '\t';
}
tmplen = strlen(names[i]);
memcpy(ptr, names[i], tmplen);
ptr += tmplen;
*ptr++ = ':';
strcpy(ptr, entries[i]);
ptr += strlen(entries[i]);
if (i != numentries - 1) {
*ptr++ = ',';
}
*ptr++ = '\n';
*ptr = 0;
free(names[i]);
free(entries[i]);
}
free(names);
free(entries);
/* 填充每一行左侧的tab */
for (i = 0; i < depth - 1; i++) {
*ptr++ = '\t';
}
*ptr++ = '}';
*ptr++ = 0;
return out;
}函数核心思想
获取json解析的关键元素
输出一个object时,需要获取层数、当前层有多少个元素这两个关键信息
- 当前是在哪一层,与递归的深度相同,获取递归深度即可,存储在
depth变量中 - 本层元素数量,通过遍历当前
cJSON节点所在双向链表上有多少个成员得到,存储在numentries变量中;
存储关键元素
要输出json还需要得到,本层json元素的名称和内容这两项关键内容
- 元素的名称,通过
print_string_ptr(child->string)获取,存放在char *数组names中 - 元素的内容,通过
print_value()获取,存放在char *数组entries中
元素拼接
首先创建左侧大括号
使用一个for循环遍历当前层的所有元素,按照"名称:内容,"的形式将当前层的元素拼接起来;需要注意的是在此前解析关键元素时,对于所有类型的元素已经全部转化成了字符串。即便当前元素是一个object或是array,也不需要进行特殊处理
最后创建右侧大括号
print_array(item, 0, 1, 0)函数
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑;此处仅列出
cJSON_Print接口的逻辑,即print_array第二个参数int depth为0;第三个参数int fmt为1;第四个参数printbuffer *p为NULL的逻辑,故删除部分冗余代码
/* Render an array to text */
static char *print_array(cJSON *item, int depth, int fmt, printbuffer *p)
{
char **entries;
char *out = 0, *ptr, *ret;
int len = 5;
cJSON *child;
child = item->child;
int numentries=0, i=0;
size_t tmplen=0;
while (child) {
numentries++, child = child->next;
}
entries=(char**)malloc(numentries * sizeof(char*));
memset(entries, 0, numentries * sizeof(char*));
child = item->child;
while (child) {
ret = print_value(child, depth + 1, fmt, 0);
entries[i] = ret;
i++;
len += strlen(ret) + 2 + (fmt ? 1 : 0);
child = child->next;
}
out=(char*)malloc(len);
*out = '[';
ptr = out + 1;
*ptr = 0;
for (i = 0; i < numentries; i++) {
tmplen = strlen(entries[i]);
memcpy(ptr, entries[i], tmplen);
ptr += tmplen;
if (i != numentries - 1) {
*ptr++ = ',';
*ptr++ = ' ';
*ptr = 0;
}
free(entries[i]);
}
free(entries);
*ptr++ = ']';
*ptr++ = 0;
return out;
}函数核心思想
print_array()函数的设计与print_object()函数的设计,如出一辙。均是解析关键元素、存储关键元素、拼接关键元素三步走。
print_array()函数print_object()函数与不同点
print_array()函数不记录当前层数;在print_object()函数中记录层数,主要是为了在拼接元素时在每一行开头输出对应数量的tabprint_array()函数记录每个成员的名称,由于array中的元素并不以键值对的形式存在而是一个个独立的字符串或数字,所以并不需要区分元素的名称和内容;
print_number(item, 0)函数
取出item->valuedouble后根据值的,根据不同的精度将结果写入之前申请的内存中
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑;此处仅列出
cJSON_Print接口的逻辑,即print_number第二个参数printbuffer *p为NULL的逻辑,故删除部分冗余代码
/* Render the number nicely from the given item into a string. */
static char *print_number(cJSON *item, printbuffer *p)
{
char *str = 0;
double d = item->valuedouble;
/*
* 根据valuedouble值的不同,分配不同长度的内存空间存储
*/
if (d == 0) {
str = (char*)malloc(2);
strcpy(str, "0");
} else if (fabs(((double)item->valueint) - d) <= DBL_EPSILON && (d <= INT_MAX && d >= INT_MIN)) {
str = (char*)malloc(21); /* 2^64+1 can be represented in 21 chars. */
sprintf(str, "%d", item->valueint);
} else {
str = (char*)malloc(64); /* This is a nice tradeoff. */
if (fabs(floor(d) - d) <= DBL_EPSILON && fabs(d) < 1.0e60) {
sprintf(str, "%.0f", d);
} else if (fabs(d) < 1.0e-6 || fabs(d) > 1.0e9) {
sprintf(str, "%e", d);
} else {
sprintf(str, "%f", d);
}
}
return str;
}函数核心思想
根据不同的数据范围分配不同长度的内存
valuedouble = 0时,分配内存长度为2字节INT_MIN <= valuedouble <= INT_MAX时,分配21字节- 更大的范围时,分配64字节
根据不同的数据范围使用不同的类型存储数据
- 对于
fabs(d) < 1.0e60表示d的绝对值小于(1.0 \times 10^{60})。在双精度浮点数范围内,使用舍弃小数部分只保留整数部分 - 如果变量
d的绝对值小于(1.0 \times 10^{-6})或者大于(1.0 \times 10^{9},将其转换为科学计数法字符串,并存储到字符串str中 - 对于其他情况转化为十进制浮点数存储
print_string(item, 0)函数
读取item中旧字符串,申请内存存放新字符串,然后将一个字符一个字符的旧字符串中的元素填充到新字符串中,对于转义字符则需要特殊处理
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑;此处仅列出
cJSON_Print接口的逻辑,即print_string第二个参数printbuffer *p为NULL的逻辑,故删除部分冗余代码
/* Invote print_string_ptr (which is useful) on an item. */
static char *print_string(cJSON *item, printbuffer *p)
{
return print_string_ptr(item->valuestring, p);
}
/* Render the cstring provided to an escaped version that can be printed. */
static char *print_string_ptr(const char *str)
{
const char *ptr;
char *ptr2, *out;
int len = 0;
unsigned char token;
ptr = str;
/* 计算待输出字符串的长度 */
while ((token =* ptr) && ++len) {
if (strchr("\"\\\b\f\n\r\t", token)) {
len++;
} else if (token < 32) {
/* 当前字符的ASCII值小于32,这些字符会被转义为类似\uXXXX 的形式,占据了5个字符的空间 */
len += 5;
}
ptr++;
}
out = (char*)malloc(len + 3);
/*
* *ptr2++ = '\\';等价于
* *ptr2 = '\\';
* ptr2++;
*/
ptr2 = out;
ptr = str;
/*
* 向之前已申请的内存空间一个字符一个字符的填充字符串
* 开头与结尾填充'\"'中间部分遍历旧字符串填充到新字符串中,对于转义字符特殊处理
*/
*ptr2++ = '\"';
while (*ptr) {
if ((unsigned char)*ptr > 31 && *ptr != '\"' && *ptr != '\\') {
*ptr2++ = *ptr++;
} else {
*ptr2++ = '\\';
switch (token = *ptr++) {
case '\\':
*ptr2++ = '\\';
break;
case '\"':
*ptr2++ ='\"';
break;
case '\b':
*ptr2++ = 'b';
break;
case '\f':
*ptr2++ = 'f';
break;
case '\n':
*ptr2++ ='n';
break;
case '\r':
*ptr2++ = 'r';
break;
case '\t':
*ptr2++ = 't';
break;
default:
sprintf(ptr2, "u%04x", token);
ptr2 += 5;
break; /* escape and print */
}
}
}
*ptr2++ = '\"';
*ptr2++ = 0;
return out;
}函数核心思想
对转义字符特殊处理
6. cJSON销毁
在cjson流程中通常会创建struct cJSON的结构体用于存储解析或构造的json内容。在流程结束后则需要销毁对应的数据结构函数接口为void cJSON_Delete(cJSON *c)
cJSON_Delete()函数
遍历整个链表,对于链表上的孩子节点做递归处理
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* Delete a cJSON structure. */
void cJSON_Delete(cJSON *c)
{
cJSON *next;
while (c) {
next = c->next;
if (!(c->type & cJSON_IsReference) && c->child) {
cJSON_Delete(c->child);
}
if (!(c->type & cJSON_IsReference) && c->valuestring) {
cJSON_free(c->valuestring);
}
if (!(c->type & cJSON_StringIsConst) && c->string) {
cJSON_free(c->string);
}
cJSON_free(c);
c = next;
}
}