参考文档:
【Linux深入】epoll源码剖析_epoll剖析-CSDN博客
epoll源码深度剖析 – 坚持,每天进步一点点 – 博客园 (cnblogs.com)
图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!-腾讯云开发者社区-腾讯云 (tencent.com)
Linux eventpoll解析 – aspirs – 博客园 (cnblogs.com)
一、 发展历史
API 发布的时间线
下文中列出了网络 IO 中,各个 api 的发布时间线
1983,socket 发布在 Unix(4.2 BSD) 1983,select 发布在 Unix(4.2 BSD) 1994,Linux的1.0,已经支持socket和select 1997,poll 发布在 Linux 2.1.23 2002,epoll发布在 Linux 2.5.44
可以看到select、poll 和 epoll,这三个“IO多路复用API”是相继发布的。这说明了,它们是IO多路复用的3个进化版本。因为API设计缺陷,无法在不改变 API 的前提下优化内部逻辑。所以用poll替代select,再用epoll替代poll
epoll和poll还有select都是监听socket的接口,poll还有select出现的时间更早,但是性能更差。后来在此继承上发展改进得到了epoll
二、epoll是什么
epoll是一种I/O事件通知机制,是linux内核实现IO多路复用的一个实现。 IO多路复用是指,在一个操作里同时监听多个输入输出源,在其中一个或多个输入输出源可用的时候返回,然后对其的进行读写操作。
epoll的通俗解释是一种当文件描述符的内核缓冲区非空的时候,发出可读信号进行通知,当写缓冲区不满的时候,发出可写信号通知的机制
三、epoll接口示例代码
创建一个epoll连接,监听标准输入。打印用户输入的值,若输入exit则直接退出结束进程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/epoll.h>
#define MAX_EVENTS 10
int main() {
int epoll_fd, nfds, n;
struct epoll_event event;
struct epoll_event events[MAX_EVENTS];
char buf[256];
// 创建一个epoll实例
epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
// 添加标准输入文件描述符到epoll实例中
event.events = EPOLLIN;
event.data.fd = STDIN_FILENO;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, STDIN_FILENO, &event) == -1) {
perror("epoll_ctl");
exit(EXIT_FAILURE);
}
while (1) {
// 等待事件发生
nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
// 处理就绪的事件
for (n = 0; n < nfds; ++n) {
if (events[n].data.fd == STDIN_FILENO) {
// 从标准输入中读取数据
if (fgets(buf, sizeof(buf), stdin) == NULL) {
perror("fgets");
exit(EXIT_FAILURE);
}
printf("Received input: %s", buf);
// 如果收到exit,则退出循环
if (strcmp(buf, "exit\n") == 0) {
goto cleanup;
}
}
}
}
cleanup:
close(epoll_fd);
return 0;
}四、核心数据结构
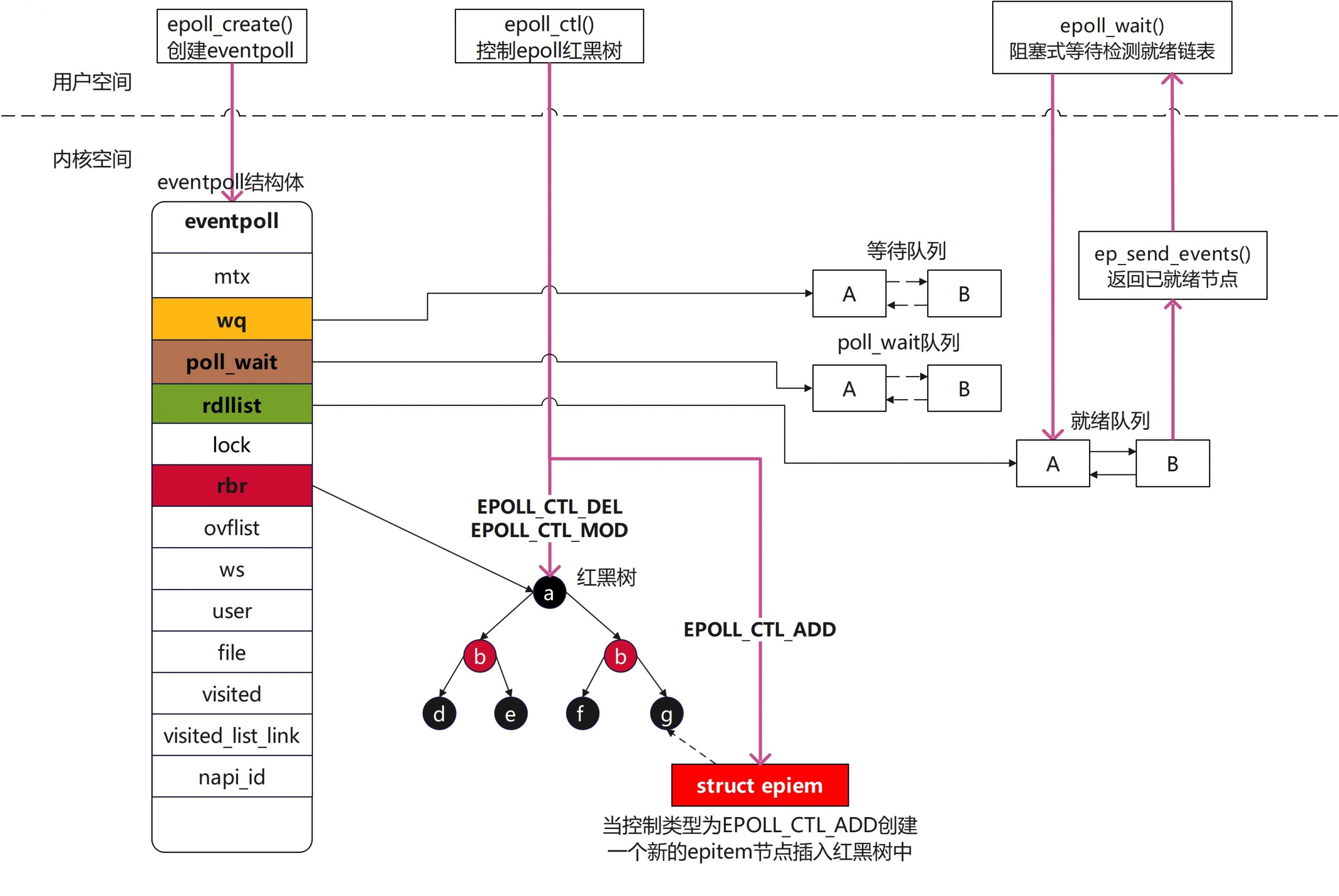
4.1 epoll核心结构体
1) struct eventpoll
这个数据结构是我们在调用epoll_create之后内核侧创建的一个句柄,表示了一个epoll实例。后续如果我们再调用epoll_ctl和epoll_wait等,都是对这个eventpoll数据进行操作,这部分数据会被保存在do_epoll_create创建的匿名文件file的private_data字段中
struct eventpoll {
/* 互斥锁 */
struct mutex mtx;
/* 等待队列,执行epoll_Wait加入等待队列*/
wait_queue_head_t wq;
/*
* 等待队列的file->poll()
* 这个队列里存放的是该eventloop作为poll对象的一个实例,加入到等待的队列
* 这是因为eventpoll本身也是一个file, 所以也会有poll操作
*/
wait_queue_head_t poll_wait;
/* 就绪链表 */
struct list_head rdllist;
/* 用于rdllist和ovflist的读写锁 */
rwlock_t lock;
/* 指向被检视对象存储的红黑树 */
struct rb_root_cached rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
struct wakeup_source *ws;
/* 创建eventpoll描述符的用户 */
struct user_struct *user;
/* eventloop对应的匿名文件 */
struct file *file;
/* 用于检测是否有嵌套调用造成环路 */
int visited;
struct list_head visited_list_link;
/* 用于追踪忙poll的napi_id */
unsigned int napi_id;
};创建eventpoll节点
ep_alloc函数
分配eventpoll节点内存,初始化epoll红黑树和等待链表
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static int ep_alloc(struct eventpoll **pep)
{
struct user_struct *user;
struct eventpoll *ep;
/* 返回当前进程的用户ID */
user = get_current_user();
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
/* 初始化互斥锁 */
mutex_init(&ep->mtx);
/* 初始化读写锁 */
rwlock_init(&ep->lock);
init_waitqueue_head(&ep->wq);
init_waitqueue_head(&ep->poll_wait);
INIT_LIST_HEAD(&ep->rdllist);
ep->rbr = RB_ROOT_CACHED;
ep->ovflist = EP_UNACTIVE_PTR;
ep->user = user;
*pep = ep;
return 0;
}核心思想
ep_alloc函数创建申请结构体的内存空间,将结构体的各个成员初始化,其中需要注意的是user保存的是当前进程对应的用户ID
eventpoll结构图
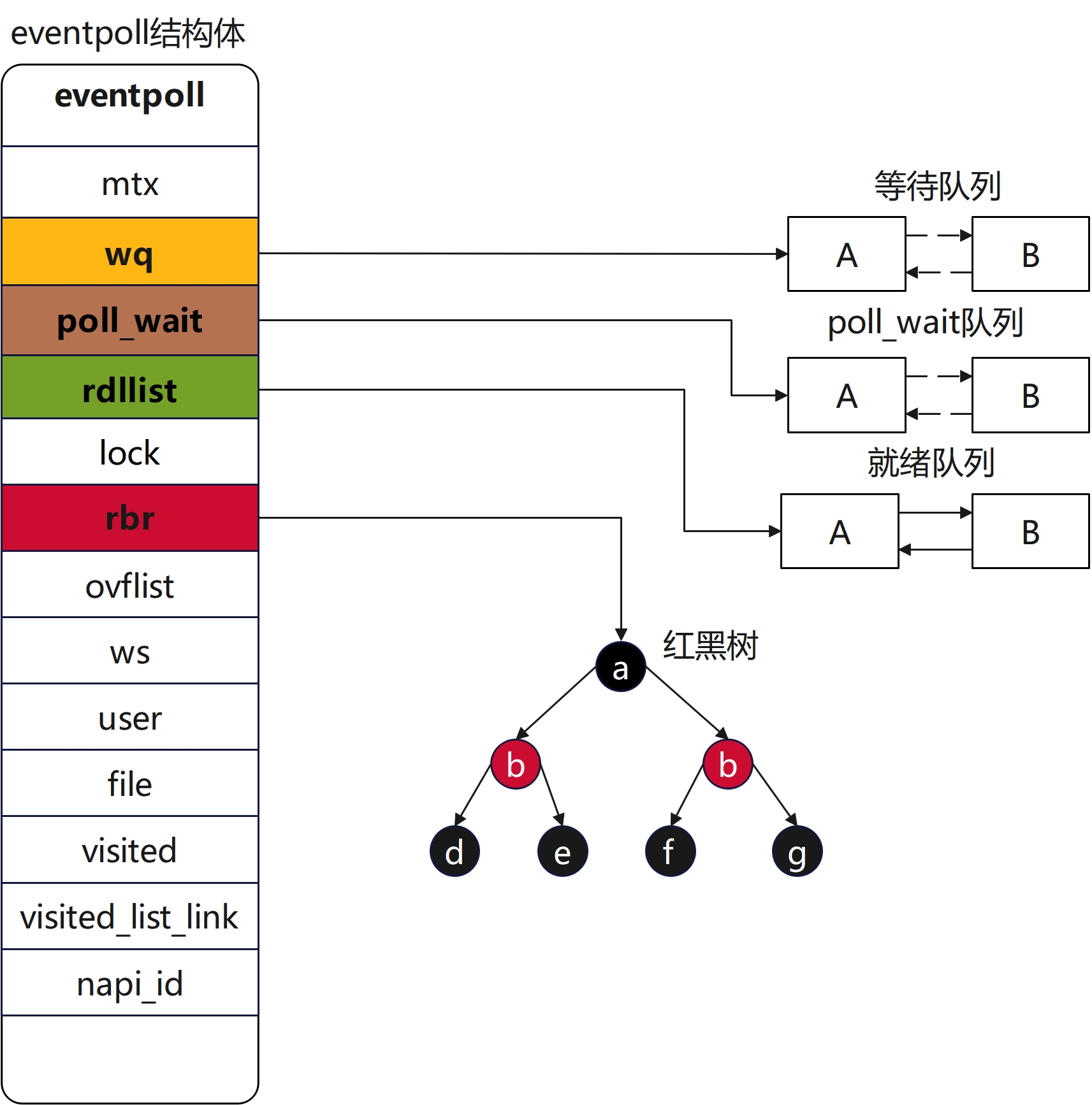
2) struct epitem
每当我们调用epoll_ctl增加一个fd时,内核就会为我们创建出一个epitem实例,并且把这个实例作为红黑树的一个子节点,增加到eventpoll结构体中的红黑树中,对应的字段是rbr。这之后,查找每一个fd上是否有事件发生都是通过红黑树上的epitem来操作
struct epitem {
union {
/* 红黑树节点将此结构链接到eventpoll红黑树 */
struct rb_node rbn;
/* RCU头部,用于释放struct epitem */
struct rcu_head rcu;
};
/* 挂载到eventpoll->rdllist的节点 */
struct list_head rdllink;
/* 指向eventpoll->ovflist的指针 */
struct epitem *next;
/* epoll监听的fd */
struct epoll_filefd ffd;
/* 一个文件可以被多个epoll实例所监听,这里记录了当前文件被监听的次数 */
int nwait;
/* 轮询等待队列的列表 */
struct list_head pwqlist;
/* 当前epollitem所属的eventpoll*/
struct eventpoll *ep;
/* 列表头文件,用于将该项链接到"struct file"的项列表 */
struct list_head fllink;
/* 设置EPOLLWAKEUP标志时使用的唤醒源 */
struct wakeup_source __rcu *ws;
/* 描述感兴趣的事件和源fd的结构 */
struct epoll_event event;
};创建epitem节点
ep_insert函数
/*
* Must be called with "mtx" held.
*/
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
int error, pwake = 0;
__poll_t revents;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
/* 获取当前用户允许创建的epoll监听最大数量 */
user_watches = atomic_long_read(&ep->user->epoll_watches);
epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
/* 设置epoll唤醒源 */
if (epi->event.events & EPOLLWAKEUP) {
error = ep_create_wakeup_source(epi);
if (error)
goto error_create_wakeup_source;
} else {
RCU_INIT_POINTER(epi->ws, NULL);
}
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
revents = ep_item_poll(epi, &epq.pt, 1);
error = -ENOMEM;
if (epi->nwait < 0)
goto error_unregister;
list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links);
ep_rbtree_insert(ep, epi);
error = -EINVAL;
if (full_check && reverse_path_check())
goto error_remove_epi;
if (revents && !ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
/* 原子地增加当前用户或进程使用的 epoll 监视器的计数 */
atomic_long_inc(&ep->user->epoll_watches);
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
error_remove_epi:
spin_lock(&tfile->f_lock);
list_del_rcu(&epi->fllink);
spin_unlock(&tfile->f_lock);
rb_erase_cached(&epi->rbn, &ep->rbr);
error_unregister:
ep_unregister_pollwait(ep, epi);
/*
* We need to do this because an event could have been arrived on some
* allocated wait queue. Note that we don't care about the ep->ovflist
* list, since that is used/cleaned only inside a section bound by "mtx".
* And ep_insert() is called with "mtx" held.
*/
write_lock_irq(&ep->lock);
if (ep_is_linked(epi))
list_del_init(&epi->rdllink);
write_unlock_irq(&ep->lock);
wakeup_source_unregister(ep_wakeup_source(epi));
error_create_wakeup_source:
kmem_cache_free(epi_cache, epi);
return error;
}核心思想
整个函数可以分为前中后三部分
- 函数的前半段主要是创建
struct epitem *epi并对其内容进行填充,这同时也是红黑树节点的类型 - 然后将
epi添加到红黑树中 - 将节点添加到对应的就绪链表、等待链表,以及设置回调函数
epitem结构图
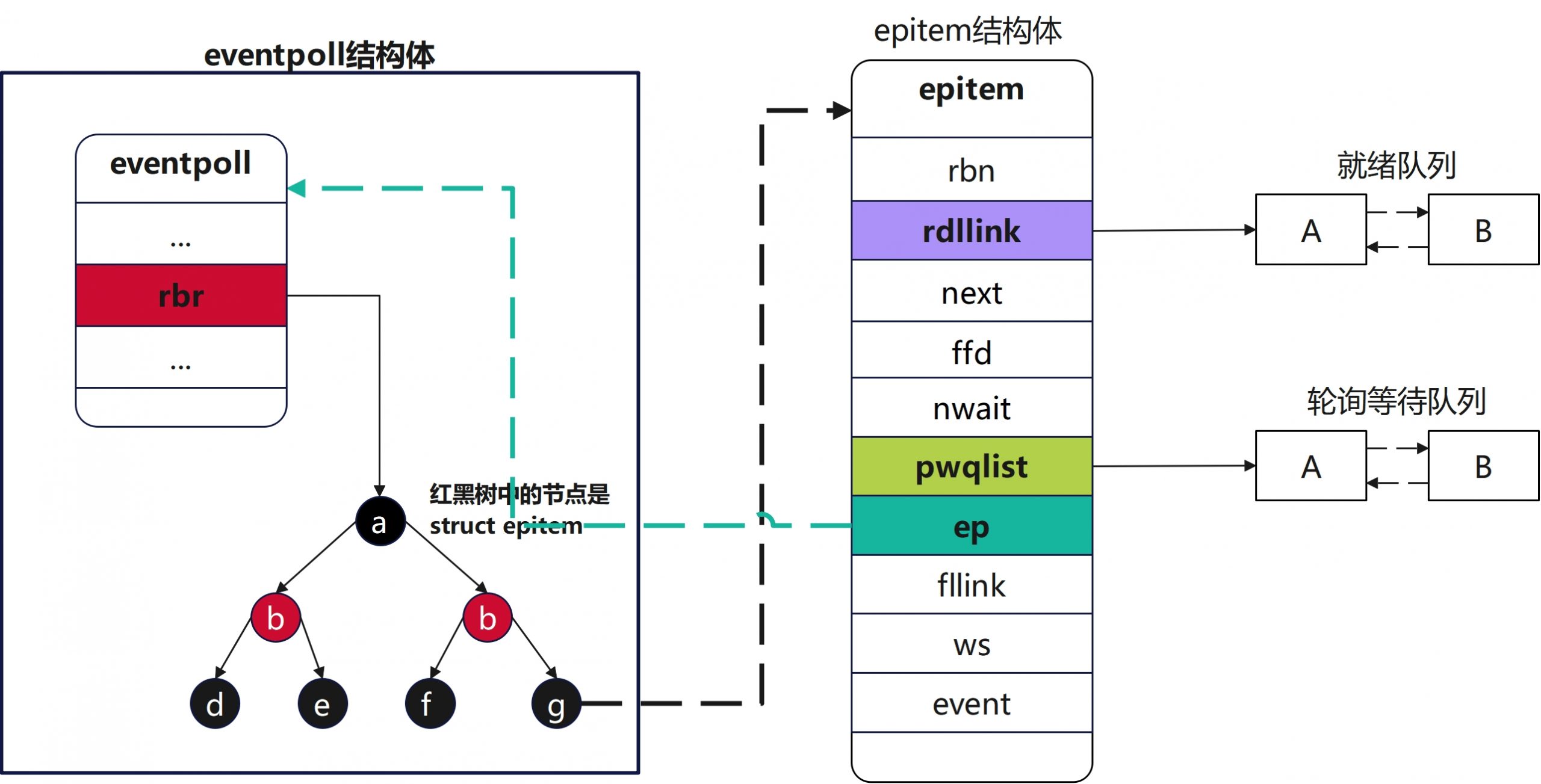
3) struct eppoll_entry
每次当一个fd关联到一个epoll实例,就会有一个eppoll_entry产生,用于轮询钩子使用的等待结构
/* Wait structure used by the poll hooks */
struct eppoll_entry
{
/* List header used to link this structure to the "struct epitem" */
struct list_head llink;
/* The "base" pointer is set to the container "struct epitem" */
struct epitem *base;
/*
* Wait queue item that will be linked to the target file wait
* queue head.
*/
wait_queue_entry_t wait;
/* The wait queue head that linked the "wait" wait queue item */
wait_queue_head_t *whead;
};4.2 epoll红黑树操作接口
epoll模块在内部维护了一个红黑树的数据结构用来管理epoll节点,红黑树的节点类型为struct epitem
1) 模块对外总接口
epoll_ctl函数
epoll模块提供的修改元素的接口,主要用于修改红黑树节点和各个关键链表
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int full_check = 0;
struct fd tf;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
copy_from_user(&epds, event, sizeof(struct epoll_event));
/*
* 接口使用时会传入对epoll节点的操作类型
* 包括增删改三种操作,分别对应不同接口
*/
switch (op) {
case EPOLL_CTL_ADD:
ep_insert(ep, &epds, tf.file, fd, full_check);
break;
case EPOLL_CTL_DEL:
ep_remove(ep, epi);
break;
case EPOLL_CTL_MOD:
ep_modify(ep, epi, &epds);
break;
}
}核心思想
对epoll节点的操作会首先进入这个函数,然后根据不同的操作类型进入不同的节点
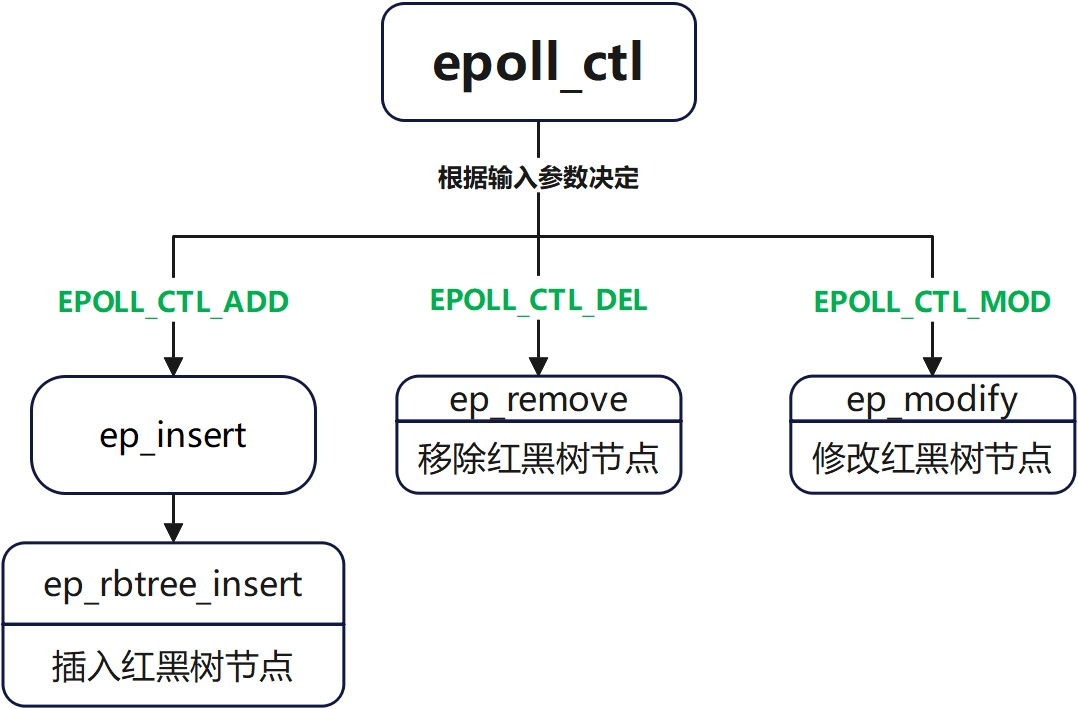
2) 查找节点
ep_find函数
在红黑树中查找节点
源代码如下
笔者注:除注释外,所有代码均未删改
static struct epitem *ep_find(struct eventpoll *ep, struct file *file, int fd)
{
int kcmp;
struct rb_node *rbp;
struct epitem *epi, *epir = NULL;
struct epoll_filefd ffd;
// 设置 epoll_filefd 结构体,用于比较查找
ep_set_ffd(&ffd, file, fd);
// 遍历红黑树
for (rbp = ep->rbr.rb_root.rb_node; rbp; ) {
/* 通过父节点获取对应的 epitem 结构体 */
epi = rb_entry(rbp, struct epitem, rbn);
/* 比较当前节点与要插入的节点 */
kcmp = ep_cmp_ffd(&ffd, &epi->ffd);
/* 如果要插入节点的关键字大于当前节点,则向右子树查找,否则向左子树查找 */
if (kcmp > 0)
rbp = rbp->rb_right;
else if (kcmp < 0)
rbp = rbp->rb_left;
else {
epir = epi;
break;
}
}
return epir;
}核心思想
采用深度优先的策略,遍历红黑树找到目标节点
3) 插入节点
ep_rbtree_insert函数
插入新的节点
源代码如下
笔者注:除注释外,所有代码均未删改
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
...
ep_rbtree_insert(ep, epi);
...
}
/* 是真正向红黑树中插入节点的函数 */
static void ep_rbtree_insert(struct eventpoll *ep, struct epitem *epi)
{
int kcmp;
struct rb_node **p = &ep->rbr.rb_root.rb_node, *parent = NULL;
struct epitem *epic;
bool leftmost = true;
/* 遍历红黑树,找到合适的插入位置 */
while (*p) {
parent = *p;
/* 通过父节点获取对应的 epitem 结构体 */
epic = rb_entry(parent, struct epitem, rbn);
/* 比较当前节点与要插入的节点 */
kcmp = ep_cmp_ffd(&epi->ffd, &epic->ffd);
/* 如果要插入节点的关键字大于当前节点,则向右子树查找,否则向左子树查找 */
if (kcmp > 0) {
p = &parent->rb_right;
leftmost = false; // 标记不是最左侧节点
} else {
p = &parent->rb_left;
}
}
/* 将新节点链接到父节点上,并重新平衡红黑树 */
rb_link_node(&epi->rbn, parent, p);
rb_insert_color_cached(&epi->rbn, &ep->rbr, leftmost);
}核心思想
采用深度优先的策略,遍历红黑树找到目标节点,然后将节点插入
4) 删除节点
ep_remove函数
从红黑树中删除节点
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{
ep_unregister_pollwait(ep, epi); // 移除轮询等待队列钩子
/* Remove the current item from the list of epoll hooks */
list_del_rcu(&epi->fllink); // 从 epoll 钩子列表中移除当前 epitem
rb_erase_cached(&epi->rbn, &ep->rbr); // 从事件轮询的红黑树中移除当前 epitem
if (ep_is_linked(epi)) // 检查当前 epitem 是否已经链接到某个链表中
list_del_init(&epi->rdllink); // 如果已链接,则从事件轮询的链表中移除
wakeup_source_unregister(ep_wakeup_source(epi)); // 取消唤醒源的注册,释放相关资源
atomic_long_dec(&ep->user->epoll_watches); // 减少 epoll 观察数计数器
return 0; // 返回成功状态
}5) 修改节点
ep_modify函数
修改节点
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/*
* Modify the interest event mask by dropping an event if the new mask
* has a match in the current file status. Must be called with "mtx" held.
*/
static int ep_modify(struct eventpoll *ep, struct epitem *epi,
const struct epoll_event *event)
{
int pwake = 0;
poll_table pt;
lockdep_assert_irqs_enabled();
init_poll_funcptr(&pt, NULL);
epi->event.events = event->events;
epi->event.data = event->data;
/*
* 检查当前节点是否设置了EPOLLWAKEUP,如果设置了,且当前 epitem 没有唤醒源,则创建一个;
* 如果未设置,且当前有唤醒源,则销毁它
*/
if (epi->event.events & EPOLLWAKEUP) {
if (!ep_has_wakeup_source(epi))
ep_create_wakeup_source(epi);
} else if (ep_has_wakeup_source(epi)) {
ep_destroy_wakeup_source(epi);
}
/* 通过vfs_poll或检查rdllink链表,判断当前节点是否准备就绪 */
if (ep_item_poll(epi, &pt, 1)) {
if (!ep_is_linked(epi)) { /* 检查当前接节点是否链接到rdllink链表上 */
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi); /* 保持epoll活跃 */
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
}
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
}4.3 关键链表及相关接口
1) epitem->ovflist链表和epitem->rdlink链表
扫描就绪链表
ep_scan_ready_list函数
扫描就绪链表核心接口,用于维护更新epoll关键链表的状态
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static __poll_t ep_scan_ready_list(struct eventpoll *ep,
__poll_t (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv, int depth, bool ep_locked)
{
__poll_t res;
int pwake = 0;
struct epitem *epi, *nepi;
/*
* 创建一个空的新链表txlist,将其和ep->rdllist拼接起来
* 此处传入的sproc是ep_read_events_proc或ep_send_events_proc用于检测句柄的状态或是将epoll检测结果从内核发给用户态
*/
LIST_HEAD(txlist);
list_splice_init(&ep->rdllist, &txlist);
WRITE_ONCE(ep->ovflist, NULL);
res = (*sproc)(ep, &txlist, priv);
/*
* 函数后半段
* 此次开始对ep->ovflist进行扫描,当ep->ovflist->rdllink中只有一个元素
* 时将其添加到ep->rdllist中并唤醒这个epi节点
*/
for (nepi = READ_ONCE(ep->ovflist); (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
if (!ep_is_linked(epi)) {
list_add(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
/* 清空ep->ovflist链表 */
WRITE_ONCE(ep->ovflist, EP_UNACTIVE_PTR);
/* 将txlist添加到ep->rdllist */
list_splice(&txlist, &ep->rdllist);
__pm_relax(ep->ws);
/* 唤醒链表 */
if (!list_empty(&ep->rdllist)) {
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return res;
}核心思想
ep_scan_ready_list函数的执行可以分为前后两个部分
前半部分:执行传入的函数指针sproc这里会根据不同的场景传入ep_read_events_proc或ep_send_events_proc,分别用于检查epoll就绪链表或将epoll检测结果从内核态发送至用户态
后半部分:遍历检查ovflist链表,根据检查结果更新rdllist链表,然后唤醒等待链表
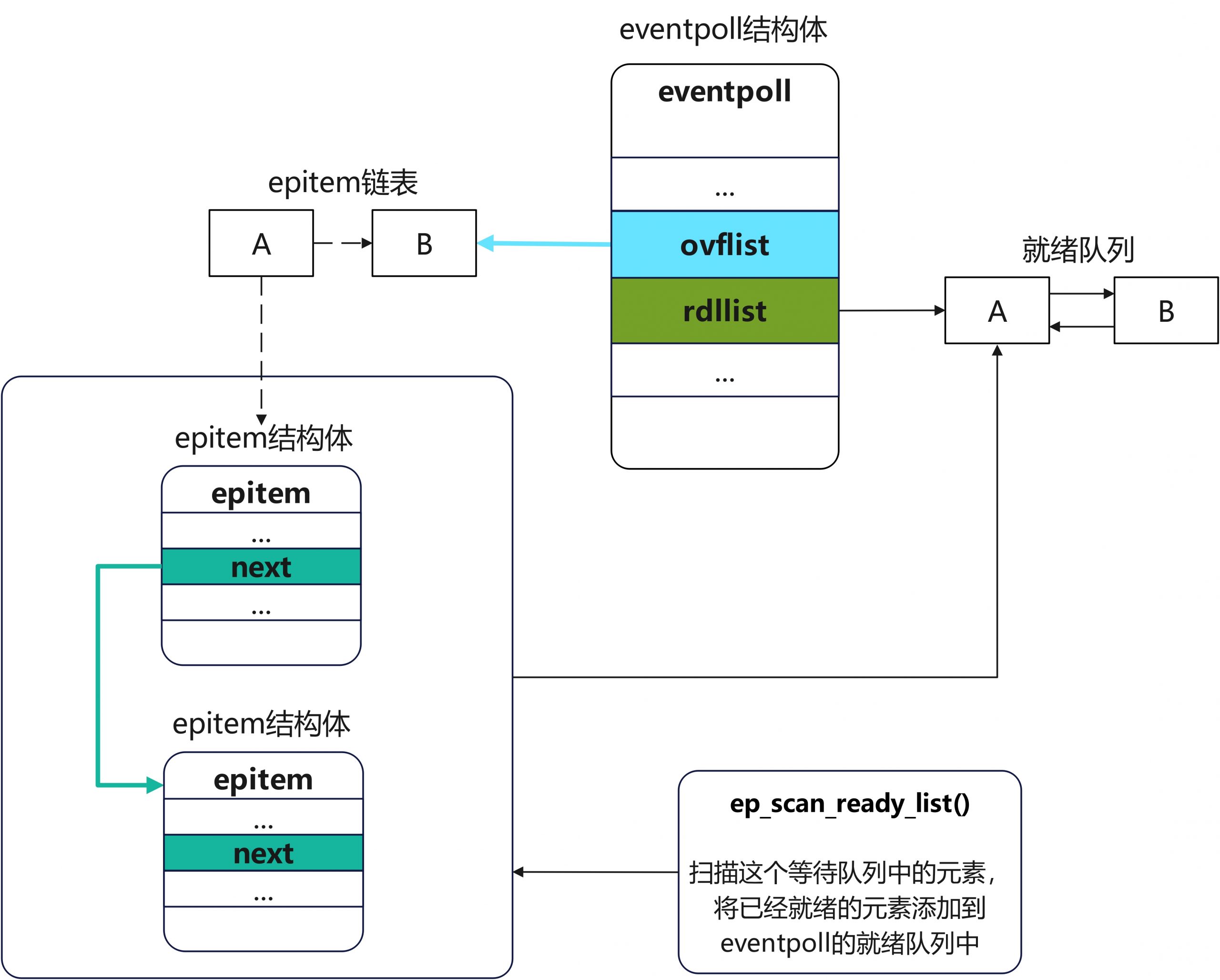
2) 等待链表和就绪链表
epitem->rdlink链表和eventpoll->rdllist链表
epitem->rdlink中存放等待的事件,eventpoll->rdllist中存放已经就绪的事件
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
...
struct epitem *epi;
/* 将epi->rdllink插入ep->rdllist尾部 */
list_add_tail(&epi->rdllink, &ep->rdllist);
...
}等待链表关系图
3) eventpoll->wq等待队列链表
函数调用栈
ep_poll
/* 此处设置的唤醒回调函数是default_wake_function,用于唤醒进程 */
->init_waitqueue_entry(&wait, current)
/* 将wait添加到eventpoll->wq链表中 */
->__add_wait_queue_exclusive(&ep->wq, &wait)
->__add_wait_queue(wq_head, wq_entry)
->list_add(&wq_entry->entry, &wq_head->head)
->__remove_wait_queue(&ep->wq, &wait)
ep_ptable_queue_proc
/* 此处设置的唤醒回调函数是ep_poll_callback,最终使用wake_up(&ep->wq)唤醒epoll */
->init_waitqueue_func_entry(&pwq->wait, ep_poll_callback)
->add_wait_queue(whead, &pwq->wait)此处注册唤醒函数后会通过wake_up接口来调用
->__wake_up
->__wake_up_common_lock
->__wake_up_common
->curr = list_next_entry(bookmark, entry);
->curr->func(curr, mode, wake_flags, key);五、对文件句柄的监听
5.1 驱动层面对文件系统的监听
file_operations->poll接口
函数声明
在linux-5.4\include\linux\fs.h中可以看到struct file_operations的定义
#define __bitwise __attribute__((bitwise))
typedef unsigned __bitwise __poll_t;
struct file_operations {
...
/* read意为读、write意为写、poll意为检测,探询 */
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
...
} __randomize_layout;函数实现
struct file_operations中的__poll_t是在驱动代码中实现,不同驱动代码实现方式不同。但都会调用poll_wait()函数
在此处列出例子
在linux-5.4\arch\powerpc\platforms\powernv\opal-prd.c中可以找到OPAL的驱动对于poll的实现
static const struct file_operations opal_prd_fops = {
...
.poll = opal_prd_poll,
...
};
static __poll_t opal_prd_poll(struct file *file,
struct poll_table_struct *wait)
{
poll_wait(file, &opal_prd_msg_wait, wait);
if (!opal_msg_queue_empty())
return EPOLLIN | EPOLLRDNORM;
return 0;
}在linux-5.4\arch\powerpc\kernel\rtasd.c中可以找到RTASD的驱动对于poll的实现
static __poll_t rtas_log_poll(struct file *file, poll_table * wait)
{
poll_wait(file, &rtas_log_wait, wait);
if (rtas_log_size)
return EPOLLIN | EPOLLRDNORM;
return 0;
}
static const struct file_operations proc_rtas_log_operations = {
...
.poll = rtas_log_poll,
...
};可以看到不同的驱动代码中都调用了poll_wait(),把当前进程加入到驱动里自定义的等待队列上,当驱动事件就绪后,就可以在驱动里自定义的等待队列上唤醒调用poll的进程。
内核等待队列
等待队列基本流程如下
在select和poll模块中自己实现了pollwake函数作为等待队列回调
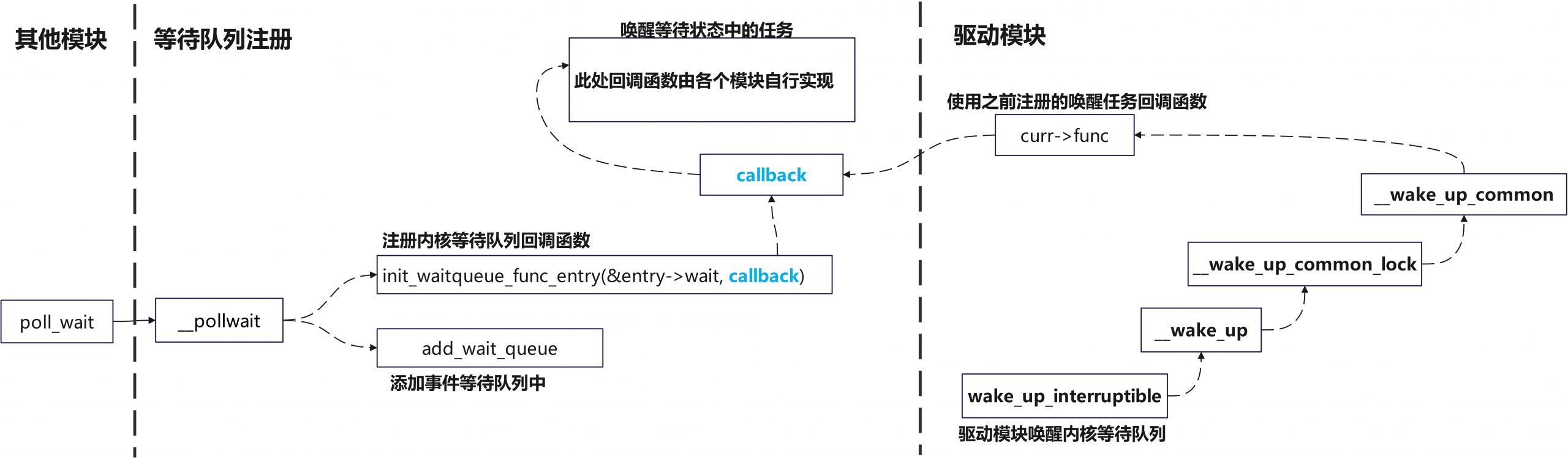
5.2 epoll对监听文件句柄的实现
关键回调函数的注册
file_operations.poll的注册
首先通过init_poll_funcptr接口注册将回调函数写入struct ep_pqueue->poll_table->_qproc
static int ep_insert(...)
{
...
struct ep_pqueue epq;
...
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
...
}在poll_wait接口中会使用刚才注册的ep_ptable_queue_proc这个回调
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}epoll对于file_operations->poll采用了自己一套实现方式,其中与驱动代码不同,并未采用poll_wait将进程挂载到内核等待链中
/* File callbacks that implement the eventpoll file behaviour */
static const struct file_operations eventpoll_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = ep_show_fdinfo,
#endif
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
};vfs_poll接口的实现
在vfs_poll接口中会调用刚才注册的ep_eventpoll_poll
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt)
{
if (unlikely(!file->f_op->poll))
return DEFAULT_POLLMASK;
return file->f_op->poll(file, pt);
}对外关键接口
在ep_item_poll接口中实现对文件的监听接口,根据不同情况分别使用vfs_poll或是ep_scan_ready_list来获取句柄状态
/*
* Differs from ep_eventpoll_poll() in that internal callers already have
* the ep->mtx so we need to start from depth=1, such that mutex_lock_nested()
* is correctly annotated.
*/
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
struct eventpoll *ep;
bool locked;
pt->_key = epi->event.events;
if (!is_file_epoll(epi->ffd.file))
return vfs_poll(epi->ffd.file, pt) & epi->event.events;
ep = epi->ffd.file->private_data;
poll_wait(epi->ffd.file, &ep->poll_wait, pt);
locked = pt && (pt->_qproc == ep_ptable_queue_proc);
return ep_scan_ready_list(epi->ffd.file->private_data,
ep_read_events_proc, &depth, depth,
locked) & epi->event.events;
}六、关键流程回调函数
1) ep_poll_safewake函数
唤醒等待eventpoll文件的状态就绪的进程
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
#define wake_up_poll(x, m) \
__wake_up(x, TASK_NORMAL, 1, poll_to_key(m))
static void ep_poll_safewake(wait_queue_head_t *wq)
{
wake_up_poll(wq, EPOLLIN);
}2) ep_poll_callback函数
epoll回调函数
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static int ep_poll_callback(wait_queue_entry_t *wait,
unsigned mode, int sync, void *key)
{
}3) ep_create_wakeup_source函数
创建唤醒源
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static int ep_create_wakeup_source(struct epitem *epi)
{
}4) ep_destroy_wakeup_source函数
销毁唤醒源
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* rare code path, only used when EPOLL_CTL_MOD removes a wakeup source */
static noinline void ep_destroy_wakeup_source(struct epitem *epi)
{
}5) ep_ptable_queue_proc函数
将等待队列添加到目标文件唤醒列表中的回调函数
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
}6) poll_wait函数
注册等待函数,将等待的回调函数注册到当前进程中,在ep_insert中使用
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/*
* structures and helpers for f_op->poll implementations
*/
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
typedef struct poll_table_struct {
poll_queue_proc _qproc;
__poll_t _key;
} poll_table;
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}7) ep_send_events_proc函数
将events事件从内核空间发送到用户空间
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
}七、epoll基本流程
7.1 epoll基本流程
7.2 创建epoll实例接口
epoll_create1和epoll_create接口均可用于创建epoll实例,不同的是epoll_create1可以多传入一个参数
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
return do_epoll_create(flags);
}
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return do_epoll_create(0);
}do_epoll_create函数
创建新的epoll节点
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/* File callbacks that implement the eventpoll file behaviour */
static const struct file_operations eventpoll_fops = {
.show_fdinfo = ep_show_fdinfo,
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
};
/*
* anon_inode_getfile-通过连接一个匿名inode和一个描述文件“类”的dentry来创建一个新的文件实例
* @name:新文件的“类”的名称
* @fops:文件操作的新文件
* @priv:新文件的私有数据(将是文件的private_data)
* @flags:打开文件的行为和属性
*
* 通过将一个文件挂接在单个索引节点上来创建一个新文件。这对于不需要完整inode就可以正确操作的文件很有用。
* 使用anon_inode_getfile()创建的所有文件将共享一个inode,从而节省内存并避免文件/inode/dentry设置的代码重复。返回新创建的文件*或错误指针。
*/
struct file *anon_inode_getfile(const char *name, const struct file_operations *fops, void *priv, int flags);
static int do_epoll_create(int flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
ep_alloc(&ep);
// 获取一个可读可写的未被使用的文件描述符
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
// 创建一个匿名的inode节点
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep, O_RDWR | (flags & O_CLOEXEC));
ep->file = file;
fd_install(fd, file);
return fd;
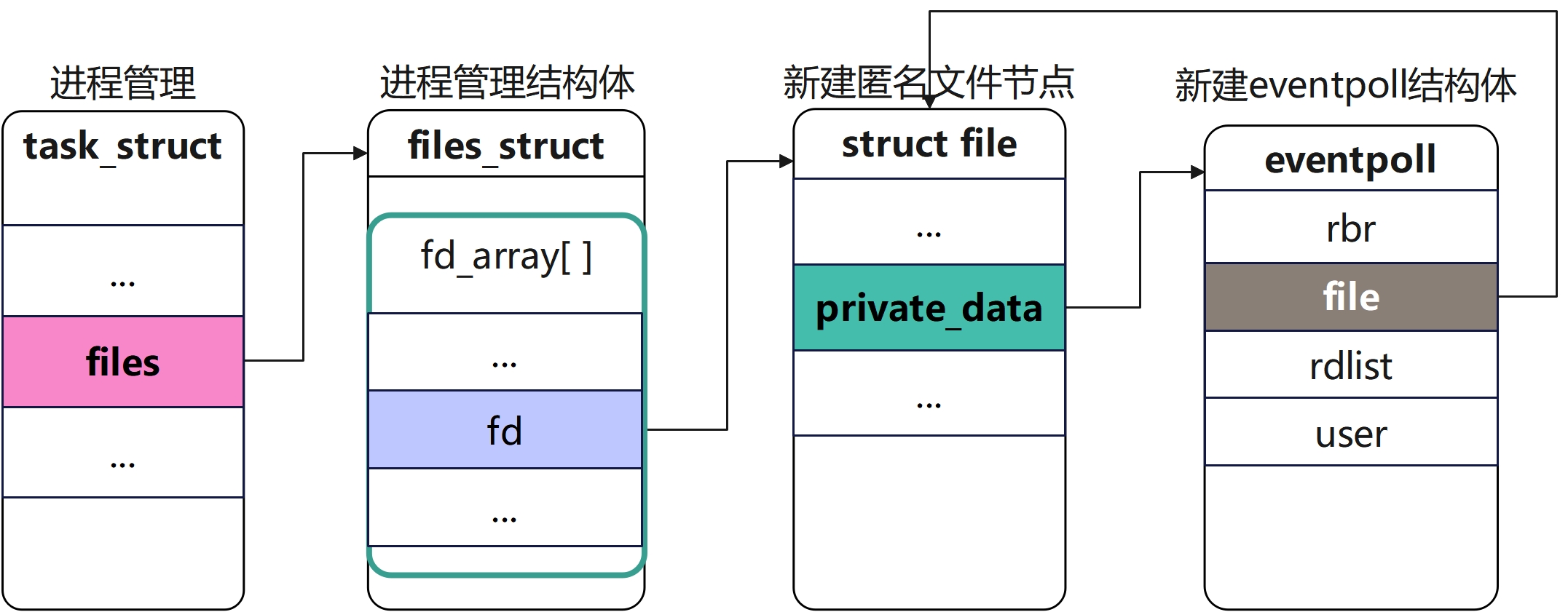
}核心思想
创建inode节点
创建一个匿名的inode节点,这个文件对象通常不对应于实际的文件系统中的任何文件,因此被称为匿名inode。它被用作epoll实例的文件描述符,通过这个文件描述符,用户空间程序可以对epoll实例进行I/O操作。并返回与之关联的文件描述符
使用anon_inode_getfile创建inode节点,此处不详细展开实现代码,仅列出函数调用栈
/* 将新建的file->private_data赋值为priv */
|->anon_inode_getfile(const char *name, const struct file_operations *fops,
void *priv, int flags)
/* 设置新建的file的名称为之前传入的name*/
|->alloc_file_pseudo(struct inode *inode, struct vfsmount *mnt, const char *name, int flags,
const struct file_operations *fops)
/* 将新建的file->f_op赋值为入参eventpoll_fops */
|->alloc_file(const struct path *path, int flags, const struct file_operations *fop)
/* 创建一个空的file对象,设置被创建文件的状态和属性为flags */
|->alloc_empty_file(int flags, const struct cred *cred)使用fd_install将新创建的inode节点插入当前进程的文件数组中
void fd_install(unsigned int fd, struct file *file)
{
/* current->files是指向当前进程文件描述符表的指针 */
__fd_install(current->files, fd, file);
}
/* fd:文件描述符
* file:新建的inode节点
* struct fdtable:内核中用来管理文件描述符的数据结构
* fdt->fd:存储file结构体的数组:
*/
void __fd_install(struct files_struct *files, unsigned int fd, struct file *file)
{
struct fdtable *fdt;
fdt = files_fdtable(files);
rcu_assign_pointer(fdt->fd[fd], file);
}此处将新建的file节点插入,对应当前的进程文件数组中,用于后续内核管理。
将其插入ep中,此时的ep是存放在等待队列中的
7.3 操作监听句柄
epoll_ctl函数
用于向epoll实例中添加、修改或删除感兴趣的文件描述符(socket、文件等)及其关注的事件
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/*
* @epfd: epool_create创建的用于eventpoll的fd
* @op: 控制的命令类型
* EPOLL_CTL_ADD:添加一个新的文件描述符和其关注的事件到 epoll 实例中。
* EPOLL_CTL_MOD:修改一个已经存在的文件描述符关注的事件。
* EPOLL_CTL_DEL:从 epoll 实例中删除一个文件描述符。
*
* @fd: 要操作的文件描述符
* @event:与fd相关的对象,描述了要添加、修改或删除的事件。
*/
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
/* 从用户空间拷贝event至内核空间 */
copy_from_user(&epds, event, sizeof(struct epoll_event));
tf = fdget(fd);
if (ep_op_has_event(op))
ep_take_care_of_epollwakeup(&epds);
ep = f.file->private_data
/*
* 句柄epfd对应的文件描述符表
* f.file->private_data存储的是此前epoll_create中新增的eventpoll节点
* 在eventpoll中存储文件描述符信息的红黑树中查找指定的fd对应的epitem实例
*/
f = fdget(epfd);
if (op == EPOLL_CTL_ADD) {
if (!list_empty(&f.file->f_ep_links) || is_file_epoll(tf.file)) {
full_check = 1;
if (is_file_epoll(tf.file)) {
error = -ELOOP;
if (ep_loop_check(ep, tf.file) != 0) {
clear_tfile_check_list();
goto error_tgt_fput;
}
} else
/* 将目标文件添加到epoll全局的tfile_check_list中 */
list_add(&tf.file->f_tfile_llink, &tfile_check_list);
}
}
epi = ep_find(ep, tf.file, fd);
switch (op) {
case EPOLL_CTL_ADD:/* 新增节点 */
if (!epi)
error = ep_insert(ep, &epds, tf.file, fd, full_check);
else
error = -EEXIST;
/* 清空文件检查列表 */
if (full_check)
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:/* 删除节点 */
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD:/* 修改节点 */
if (epi) {
error = ep_modify(ep, epi, &epds);
else
error = -ENOENT;
break;
}
fdput(tf);
fdput(f);
error_return:
return error;
}核心思想
epoll_ctl接口主要用于对想要监视的file做增删改的操作,将数据从用户空间拷贝至内核空间然后根据不同的操作类型调用不同的接口
使用fdget接口获取句柄对应的进程描述符task_struct,然后通过task_struct操作eventpoll
相关接口及调用栈
ep_insert
->reverse_path_check
/* tfile_check_list链表 */
->list_for_each_entry
/* 此处remove接口操作的其实是一个eppoll_entry链表 */
ep_remove
->ep_unregister_pollwait
->ep_remove_wait_queue
ep_modify
->ep_pm_stay_awake7.4 等待epoll事件
epoll_wait函数
对ep_poll的一层封装
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
return do_epoll_wait(epfd, events, maxevents, timeout);
}
static int do_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, int timeout)
{
int error;
struct fd f;
struct eventpoll *ep;
f = fdget(epfd);
ep = f.file->private_data;
error = ep_poll(ep, events, maxevents, timeout);
fdput(f);
return error;
}ep_poll函数
这个函数真正将执行epoll_wait的进程带入睡眠状态
核心逻辑如下
笔者注:下文代码已格式化处理,并适当简化只保留核心逻辑
/*
* ep_poll - 检索准备好的事件,并将它们传递到调用者提供的事件缓冲区
*
* @ep: 指向eventpoll上下文的指针
* @events: 指向用户空间缓冲区的指针,准备好的事件应该存储在这里
* @maxevents: 调用者事件缓冲区的大小(以事件数量表示)
* @timeout: 准备事件获取操作的最大超时时间,单位为毫秒。如果@timeout为零,则该函数不会阻塞
* 而如果@timeout小于零,则该函数将阻塞,直到至少检索到一个事件(或发生错误)
*/
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res = 0, eavail, timed_out = 0;
u64 slack = 0;
bool waiter = false;
wait_queue_entry_t wait;
ktime_t expires, *to = NULL;
lockdep_assert_irqs_enabled();
/* timeout大于0时,获取高精度定时器的误差值 */
if (timeout > 0) {
slack = select_estimate_accuracy(&timeout);
} else if (timeout == 0) {
/* timeout等于0时,将timed_out置为1跳转后会直接进入等待流程 */
timed_out = 1;
eavail = ep_events_available(ep);
goto send_events;
}
fetch_events:
/* 如果没有可用事件,就调用ep_busy_loop()函数进行忙等待,直到有事件变为可用或者超时 */
if (!ep_events_available(ep))
ep_busy_loop(ep, timed_out);
/* 获取epoll实例中当前可用事件数 */
eavail = ep_events_available(ep);
if (eavail)
goto send_events;
ep_reset_busy_poll_napi_id(ep);
/*
* waiter表示当前进程是否存在于等待队列中
* init_waitqueue_entry初始化一个等待队列,将当前队列和wait关联
* __add_wait_queue_exclusive将当前进程添加到等待队列中
* 以便在事件不可用时进入睡眠状态,等待事件的发生
*/
if (!waiter) {
waiter = true;
init_waitqueue_entry(&wait, current);
__add_wait_queue_exclusive(&ep->wq, &wait);
}
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
/* 若此时有新的可用事件则跳出循环 */
eavail = ep_events_available(ep);
if (eavail)
break;
/* 设置高精度超时定时器,若超时则跳出循环 */
if (!schedule_hrtimeout_range(timeout, slack, HRTIMER_MODE_ABS)) {
timed_out = 1;
break;
}
}
set_current_state(TASK_RUNNING);
send_events:
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
/* 当 epoll 实例中有可用事件、事件发送成功、且没有发生超时重新执行fetch_events */
if (eavail && !(res = ep_send_events(ep, events, maxevents)) && !timed_out)
goto fetch_events;
if (waiter) {
__remove_wait_queue(&ep->wq, &wait);
}
return res;
}核心思想
ep_poll通过高精度定时器和进程忙等待,在不断地循环中通过ep_events_available()检测可用事件。最终将可用事件存储在events中
关键接口函数调用栈
/* 此处检查的是就绪链表的内容 */
ep_events_available(struct eventpoll *ep)
->list_empty_careful(&ep->rdllist)八、epoll与select、poll的对比
1) 用户态将文件描述符传入内核的方式
select:创建3个文件描述符集并拷贝到内核中,分别监听读、写、异常动作。这里受到单个进程可以打开的fd数量限制,默认是1024。poll:将传入的struct pollfd结构体数组拷贝到内核中进行监听。epoll:执行epoll_create会在内核的高速cache区中建立一颗红黑树以及就绪链表(该链表存储已经就绪的文件描述符)。接着用户执行的epoll_ctl函数添加文件描述符会在红黑树上增加相应的结点。
2) 内核态检测文件描述符读写状态的方式
select:采用轮询方式,遍历所有fd,最后返回一个描述符读写操作是否就绪的mask掩码,根据这个掩码给fd_set赋值。poll:同样采用轮询方式,查询每个fd的状态,如果就绪则在等待队列中加入一项并继续遍历。epoll:采用回调机制。在执行epoll_ctl的add操作时,不仅将文件描述符放到红黑树上,而且也注册了回调函数,内核在检测到某文件描述符可读/可写时会调用回调函数,该回调函数将文件描述符放在就绪链表中。
3) 找到就绪的文件描述符并传递给用户态的方式
select:将之前传入的fd_set拷贝传出到用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。poll:将之前传入的fd数组拷贝传出用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。epoll:epoll_wait只用观察就绪链表中有无数据即可,最后将链表的数据返回给数组并返回就绪的数量。内核将就绪的文件描述符放在传入的数组中,所以只用遍历依次处理即可。这里返回的文件描述符是通过mmap让内核和用户空间共享同一块内存实现传递的,减少了不必要的拷贝。
4) 重复监听的处理方式
select:将新的监听文件描述符集合拷贝传入内核中,继续以上步骤。poll:将新的struct pollfd结构体数组拷贝传入内核中,继续以上步骤。epoll:无需重新构建红黑树,直接沿用已存在的即可。
九、总结
epoll更高效的原因
1)select和poll的动作基本一致,只是poll采用链表来进行文件描述符的存储,而select采用fd标注位来存放,所以select会受到最大连接数的限制,而poll不会。
2)select、poll、epoll虽然都会返回就绪的文件描述符数量。但是select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
3)select、poll都需要将有关文件描述符的数据结构拷贝进内核,最后再拷贝出来。而epoll创建的有关文件描述符的数据结构本身就存于内核态中,系统调用返回时利用mmap()文件映射内存加速与内核空间的消息传递:即epoll使用mmap减少复制开销。
4)select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多。
5)epoll的边缘触发模式效率高,系统不会充斥大量不关心的就绪文件描述符
虽然epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。